
Google планирует потратить в 2025 году 75 млрд долларов на строительство дата-центров для ИИ. А OpenAI, Oracle и другие американские гиганты хотят инвестировать в инфраструктуру для искусственного интеллекта 500 млрд долларов в течение следующих пяти лет.
Дело в том, что обучение и работа нейросетей уровня GPT-4.5 требуют невероятных мощностей. Тренинг суперэффективного DeepSeek-V3 обошёлся в 5 млн долларов — речь только о стоимости процессорного времени, без учёта затрат на сбор датасета, эксперименты, зарплаты инженеров и других обязательных костов.
Но это не значит, что для запуска большой языковой модели (LLM) нужна собственная серверная стойка. Мы уже рассказывали, как запустить дистиллированную (проще говоря, оптимизированную) модель DeepSeek-R1 на обычном компьютере. А некоторые нейросети потянут самые обычные смартфоны.
Вообще-то многие современные устройства уже укомплектованы моделями искусственного интеллекта. Например, на Google Pixel 8 и новее трудится Gemini Nano, которая реализует функции вроде «умных» ответов в клавиатуре и транскрипции аудиозаметок. Apple Intelligence в актуальных iPhone тоже во многом полагается на локальные нейросети.
А в этом материале мы рассмотрим запуск оптимизированных версий текстовых нейросетей вроде Gemma 3 от Google и Llama 3.2 от Meta*. То есть получим собственного чат-бота, который не зависит от интернета, региональных ограничений и не сливает данные корпорациям.
Основные моменты. Запустить локально можно только LLM, которые выложены в открытый доступ. Разработки OpenAI (несмотря на слово Open) к ним не относятся.
Мы будем использовать модели в оптимизированном формате GGUF — его понимают большинство инструментов для запуска LLM. Найти в официальных репозиториях GGUF-версии моделей едва ли получится. Обычно оптимизацией занимаются сторонние разработчики.
На смартфоне уровня iPhone последних двух поколений без проблем получится запустить модель размером около 3–4 млрд параметров. Скорость генерации ответов более крупными LLM настолько низкая, что их использование теряет всякий смысл.
Где искать оптимизированные модели
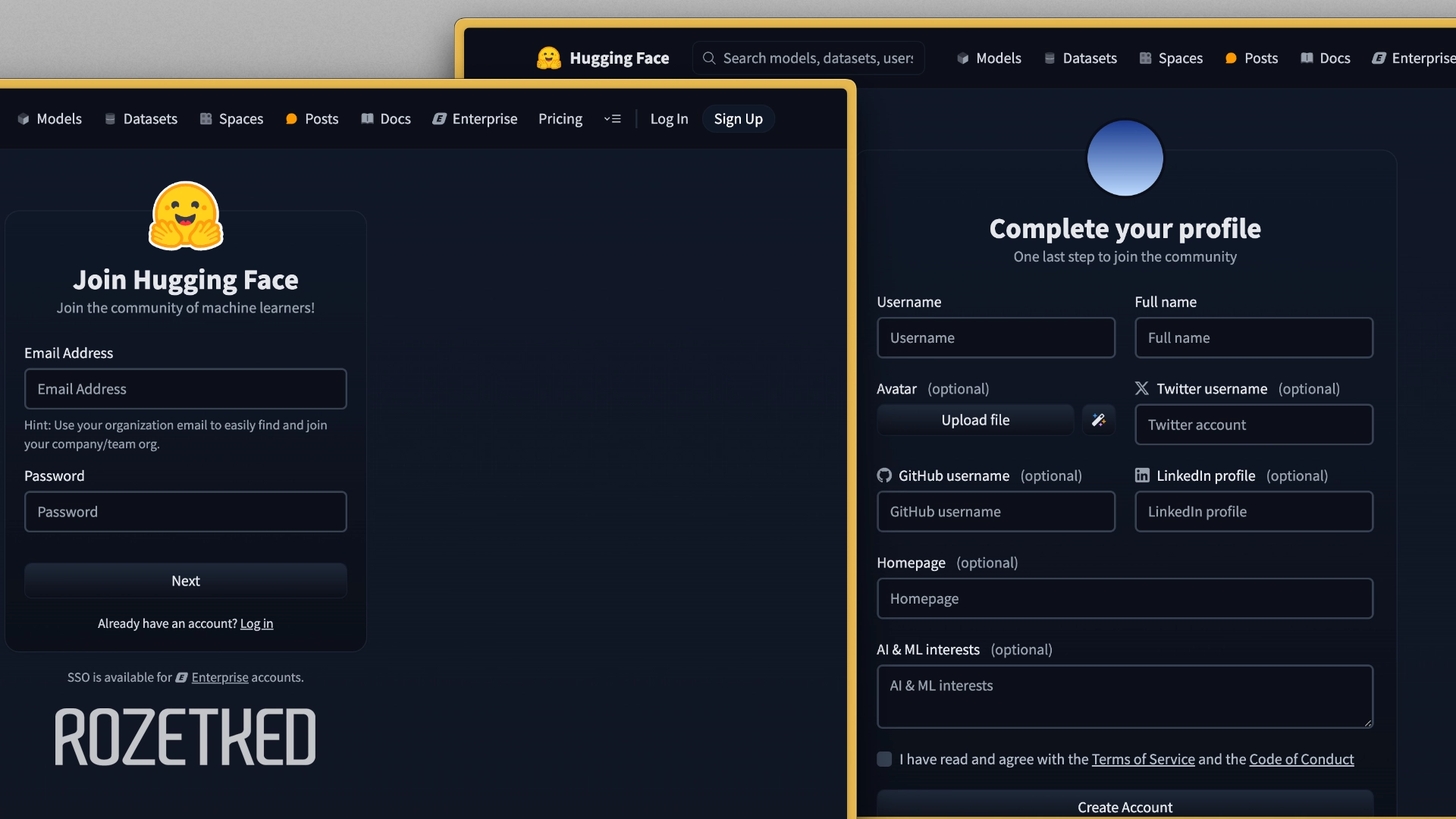
Главный репозиторий для открытых нейросетей — Hugging Face. Во многих приложениях-лаунчерах интегрирован каталог c популярными разработками, но если захотите скачивать с HF интересующие модели самостоятельно, потребуется создать учётную запись.
Интерфейс Hugging Face не переведён на русский язык, так что на всякий случай пошаговая инструкция:
- Перейдите по ссылке выше. В поле Email Address укажите адрес электронной почты, в поле Password — желаемый пароль, который содержит минимум 8 символов, заглавные, строчные буквы и цифры. Нажмите Next.
- В поле Username укажите уникальное имя пользователя, в поле Full name — имя. Остальные пункты можно оставить пустыми.
- Отметьте галочкой, что согласны с пользовательским соглашением, и нажмите Create Account. На следующем экране можно нажать Skip.
- Проверьте указанный электронный ящик и перейдите по ссылке в письме от Hugging Face, чтобы подтвердить аккаунт.
Команд, которые создают GGUF-версии популярных моделей, на площадке множество. Например, можно брать файлы у LM Studio Community, разработчиков популярного инструмента для локальных нейросетей LM Studio. В их каталоге в том числе есть:
На странице модели перейдите на вкладку Files and versions. Появится список документов: нас интересуют файлы с расширением .gguf. Обычно в репозитории лежит несколько версий модели, которые сжаты методом квантования. Всё просто: чем меньше размер файла, тем сильнее сжатие и ниже итоговая точность. Модель загружается в оперативную память, так что учитывайте характеристики смартфона при выборе. Чтобы скачать модель, нажмите на значок Download.
Как запустить нейросеть локально на смартфоне
В App Store и Google Play масса приложений для локального запуска моделей. Неплохой вариант — PocketPal AI: кроссплатформенный, бесплатный, без рекламы, поддерживает GGUF, есть встроенный поиск по Hugging Face. И без особых заморочек с настройкой.
Инструкция по первоначальной настройке:
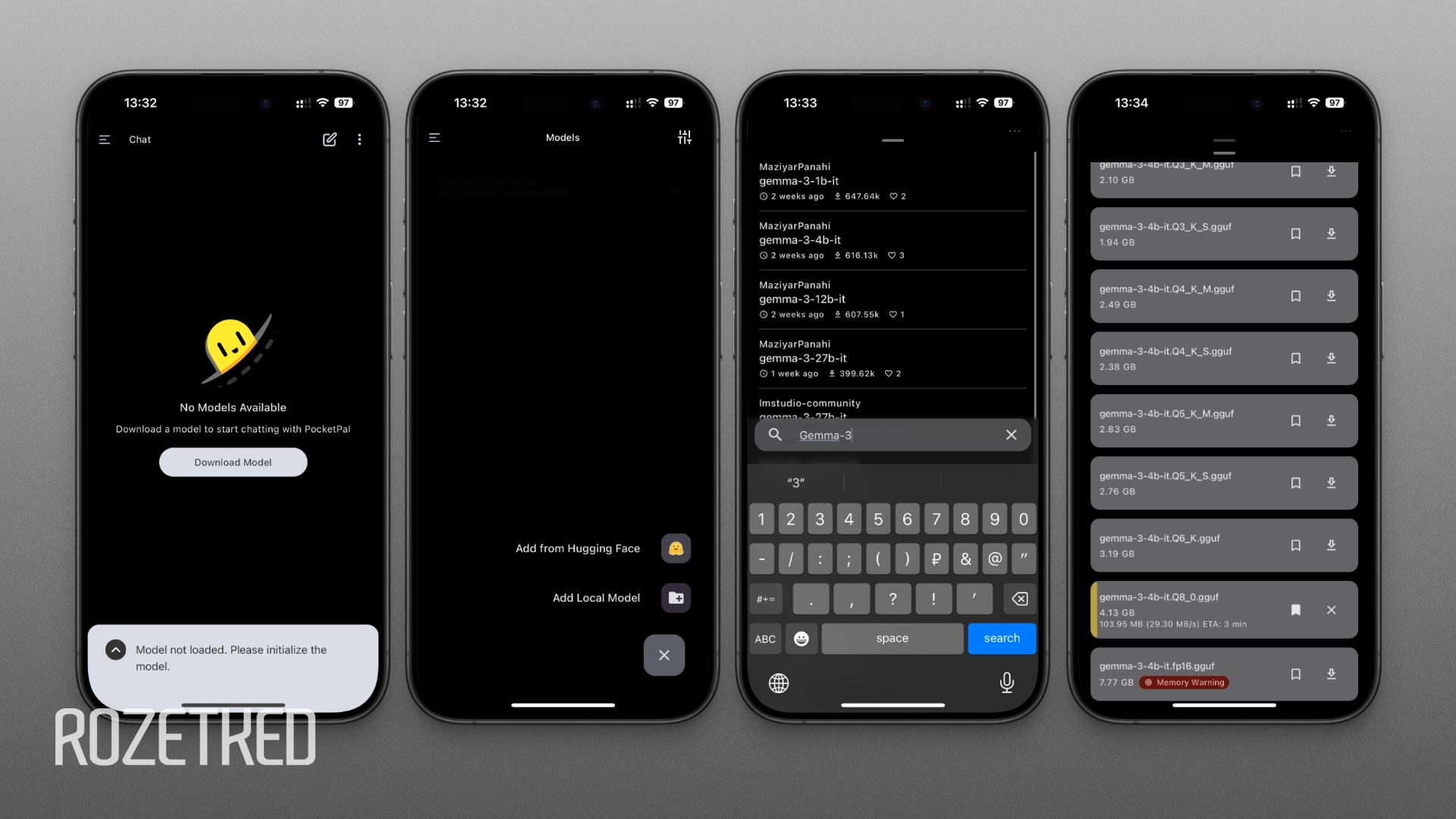
- Скачайте PocketPal из App Store или Google Play.
- На первом экране приложения нажмите на кнопку Download Model.
- Внизу справа нажмите на кнопку + и выберите Add from Hugging Face.
- В поле поиска внизу укажите название желаемой модели. Например, gemma-3, llama-3.2 или qwen-2.5. При выборе обращайте внимание на количество параметров: подходит 3b, 4b или меньше.
- На экране появится список моделей. Обычно разработчики предоставляют несколько квантованных версий. Напоминаю, что LLM загружается в ОЗУ — выбирайте версию в зависимости от характеристик смартфона.
- Нажмите на значок загрузки и дождитесь завершения скачивания.
Теперь модель готова к запуску. Вернитесь на домашний экран PocketPal (вкладка Chat в боковом меню), нажмите Select Model и выберите ранее загруженную нейросеть. Спустя несколько мгновений на экране появится чат.
В PocketPal можно загрузить несколько моделей и переключаться между ними в любой момент — естественно, выгрузив предыдущую из памяти.
Память и скорость. Размер контекста, то есть объём информации, который нейросеть может «запомнить» и использовать для составления ответа, зависит от модели. Например, оригинальная Gemma 3 на 4 млрд параметров обладает контекстным окном в 128 000 токенов, то есть 80 000–90 000 слов. У оптимизированных версий размер контекста может составлять и 8000 токенов.
PocketPal позволяет разделять контекст на разные чаты — прямо как в ChatGPT и других нейросервисах.
Скорость генерации зависит не только от модели, но и от мощности устройства. iPhone 15 Pro при помощи вышеупомянутой Gemma-3-4b c 8-битным квантованием выдаёт 8–10 токенов в секунду — долго ждать ответа не приходится, текст появляется достаточно быстро, пусть и медленнее, чем, например, Le Chat в скоростном режиме.
Создание собственных ассистентов. В приложении можно создавать «приятелей» — то есть специализированных ассистентов, как GPTs от OpenAI. Достаточно указать системный промпт, который будет автоматически подставляться перед началом диалога: например, можно попросить ИИ играть роль личного диетолога. Для создания ассистента в PocketPal:
- Перейдите на вкладку Pals в меню слева;
- Выберите Assistant и заполните поля: Pal Name (желаемое название), Default Model (одна из скачанных LLM), System Prompt (системный промпт с указаниями).
- Нажмите Create.
Для переключения между обычными моделями и «приятелями» жмите на значок стрелки вверх рядом с полем ввода запроса.
Сравнение Gemma 3, Llama 3.2 и Qwen 2.5
Запустим на iPhone 15 Pro при помощи PocketPal три модели:
- Gemma 3 на 4 млрд параметров;
- Llama 3.2 на 3 млрд параметров;
- Qwen 2.5 на 3 млрд параметров.
Все три оптимизированы путём 8-битного квантования (Q8_0). Это максимально щадящий механизм сжатия модели с минимальными потерями качества.
Через каждую нейросеть прогнали три запроса:
- «Когда вышел альбом After Hours от исполнителя Drake?».
- «В турнире по фехтованию принимали участие 20 фехтовальщиков, причём каждый из них сыграл только одну партию с каждым из остальных. Сколько всего поединков было сыграно в этом турнире?».
- «Напиши письмо подчинённому с объяснением правил email-этикета».
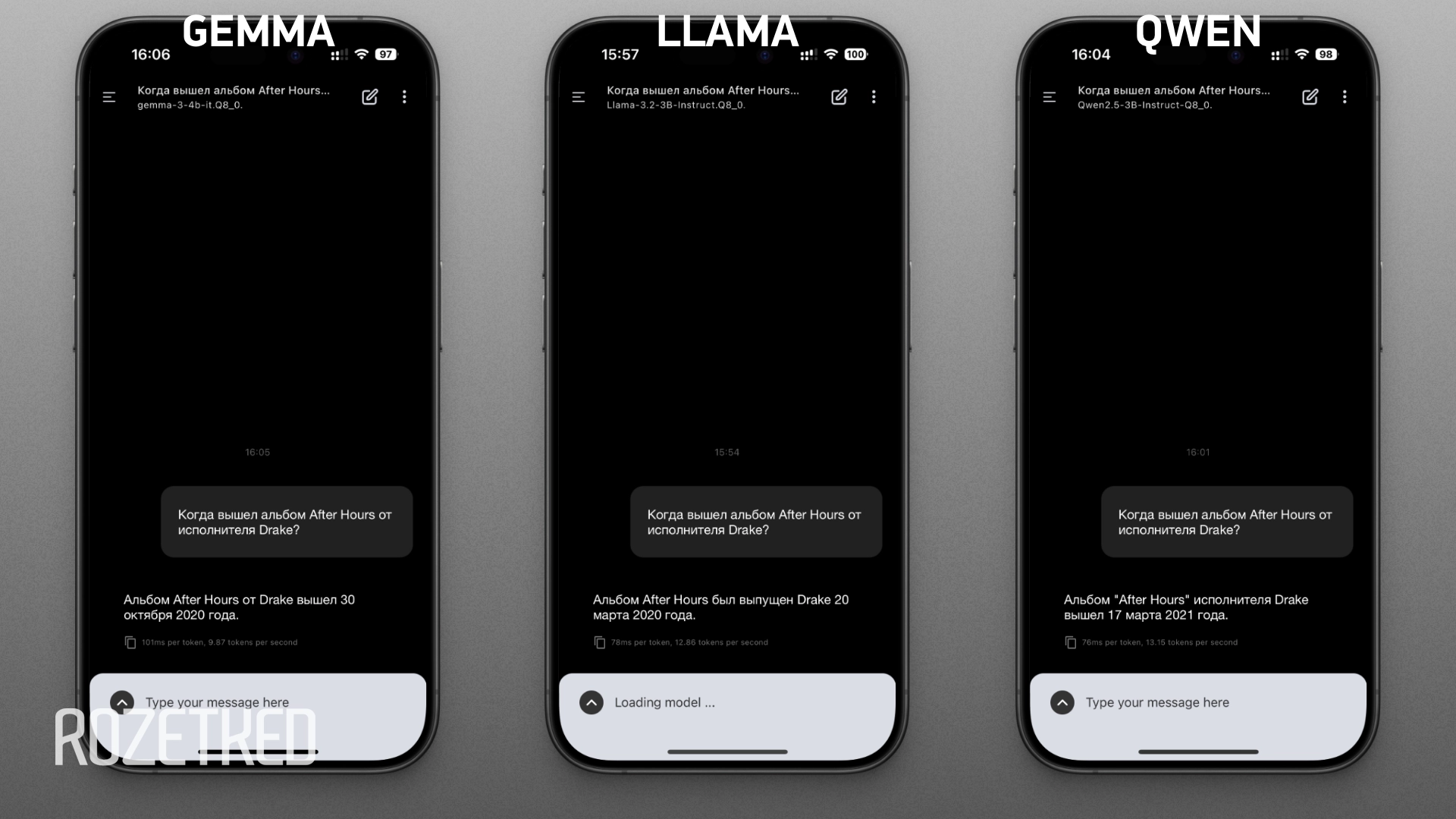
Все тестируемые нейросети попались на уловку в первом вопросе: у Drake нет альбома с таким названием. Зато есть у The Weeknd. Llama в качестве даты выхода назвала именно пластинку The Weeknd, две остальные нейросети указали случайное число.
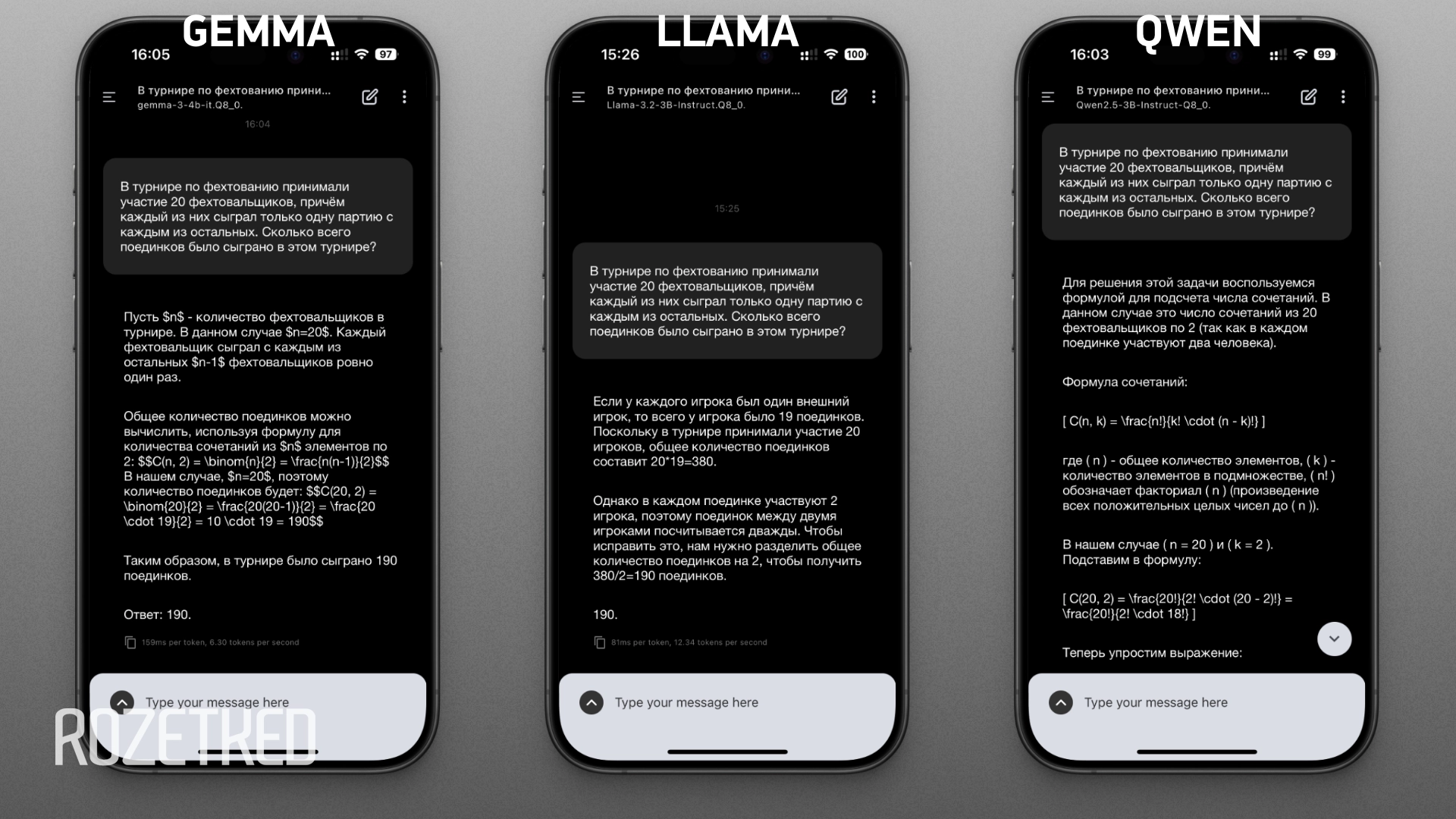
С решением математической задачи справились все. Причём Llama предложила понятный способ решения, а Gemma и Qwen ответили в виде формул. Из-за отсутствия корректного форматирования формул прочитать их невозможно.
Самый качественный и подробный ответ на третий промпт дала Gemma. Возможно, обращаться к подчинённому на «ты» — не самая удачная идея, но в остальном нейросеть дала дельные советы и даже предложила адресату готовый шаблон. Qwen предоставила слишком общие рекомендации. А вот Llama вдруг смешала русский язык с английским.
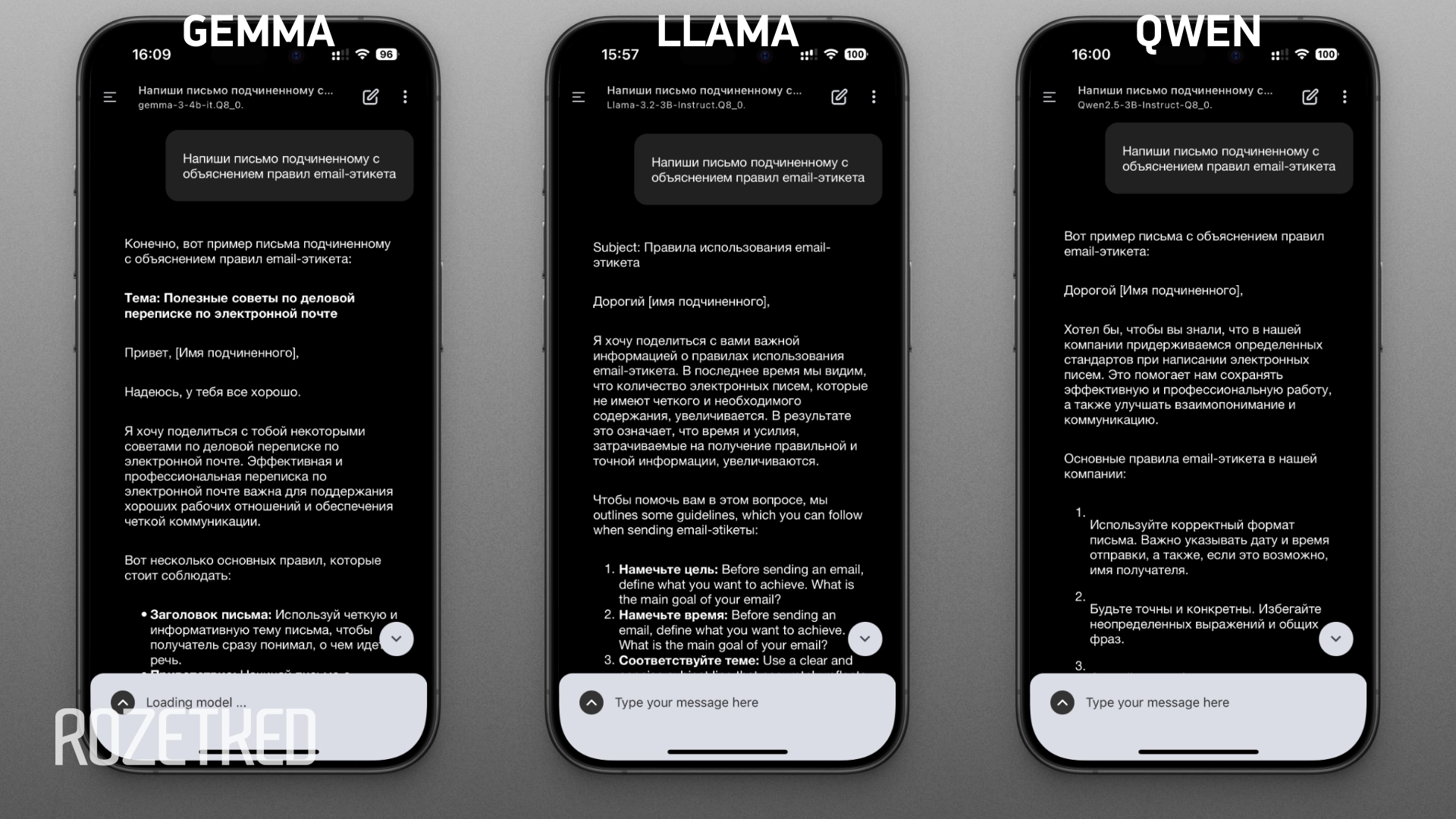
Также замерили скорость генерации: Llama и Qwen находятся примерно на одном уровне, Gemma выдаёт ответ заметно медленнее. Оно и понятно, ведь у неё 4 млрд параметров, а у конкурентов — 3 млрд.
| Средняя скорость генерации, токен/сек | |
|---|---|
| Gemma 3 | 7,47 |
| Llama 3.2 | 12,48 |
| Qwen 2.5 | 11,89 |