
У нашумевшей нейросети DeepSeek масса преимуществ: доступность, отсутствие региональных ограничений, высокая эффективность. А ещё код модели доступен публично. Это открывает новые возможности для разработчиков, которые смогут строить собственные технологии на базе DeepSeek.
А для обычных пользователей открытый код означает, что модель можно запустить локально на своём компьютере. Но как? Ведь у «рассуждающей» DeepSeek-R1 аж 671 млрд параметров, и для функционирования такой гигантской нейросети необходимы мощности серверного уровня, скажете вы.
Короткий ответ: дистилляция. Чуть менее короткий ответ: разработчики взяли основную модель DeepSeek-R1 и обучили на её основе несколько более компактных версий. Оптимизированные модели требуют меньше ресурсов, но при этом сохраняют большую часть способностей оригинала.
Так, помимо DeepSeek-R1 на 671 млрд параметров, есть модели на 7, 8, 14, 32 и 70 млрд. Например, мне удалось успешно запустить R1 на 7 млрд параметров на самом обычном MacBook Air с чипом M1 и 8 ГБ объединённой памяти.
У локальных моделей есть несколько преимуществ. Когда нейросеть работает прямо на персональном компьютере, ей не требуется доступ в интернет. А ещё ваши данные не утекут на китайские серверы — так что можно со спокойной душой делиться с чат-ботом и историей болезни, и корпоративными секретами.
Но не всё так радужно. Четырёхлетний MacBook Air выдаёт не больше трёх токенов (порядка двух слов) в секунду, хотя по ощущениям скорость генерации намного ниже: в ожидании ответа можно смело отправляться на кухню за чаем. Да и пользоваться компьютером в процессе работы модели практически невозможно. Но если вам посчастливилось владеть более мощным «железом», возможно, стоит хотя бы попробовать — тем более, ничего сложного здесь нет.
К тому же модель на 7 млрд параметров довольно… глупая. Она то и дело скачет с русского языка на китайский вперемешку с английским, а объём знаний явно скромнее, чем у полновесной DeepSeek-R1.
Как запустить DeepSeek локально при помощи LM Studio
Удобнее всего запускать локальные модели через утилиту LM Studio — с графическим интерфейсом, каталогом опенсорс-нейросетей и массой настроек. Пошагово:
- Загрузите LM Studio на компьютер под управлением Windows, macOS или Linux.
- Установите программу как обычно и запустите.
- На приветственном экране нажмите Skip onboarding вверху справа.
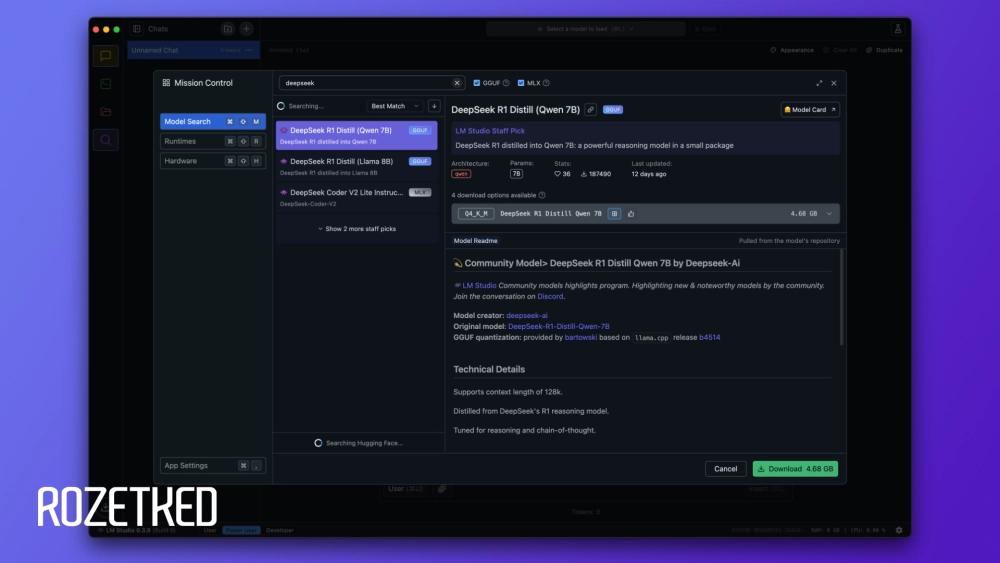
- Нажмите на значок поиска в боковой панели слева.
- В поисковом поле введите DeepSeek и выберите модель нужного размера.
- Внизу справа нажмите Download и дождитесь завершения загрузки файлов. Дистиллированный до 7 млрд параметров DeepSeek-R1 умещается в 4,7 ГБ.
- В разделе Chat можно вводить запросы и ожидать ответа. LM Studio выделит процесс «рассуждений» в отдельный блок, а под финальным ответом появится статистика по скорости генерации.
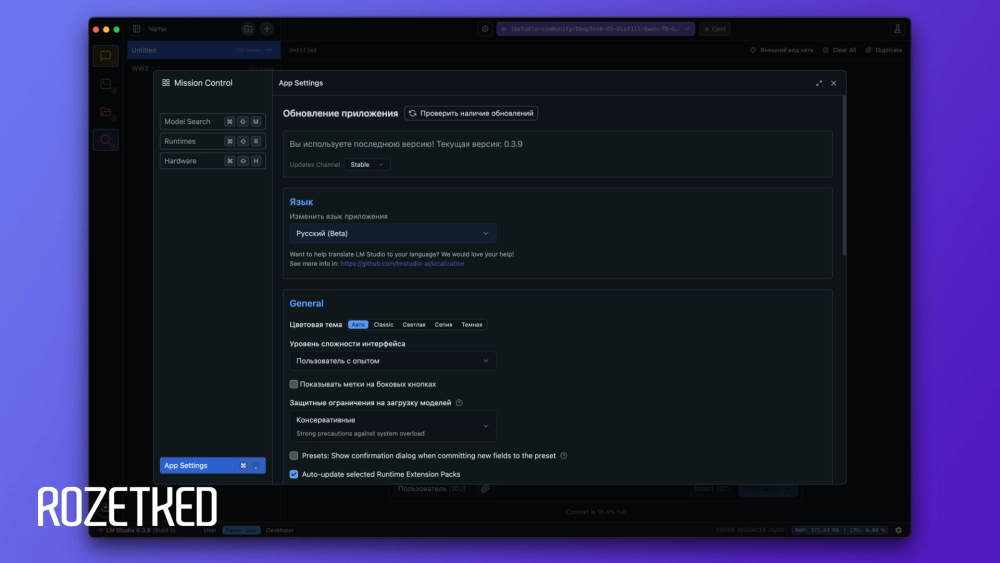
Приложение частично переведено на русский язык: нажмите на иконку шестерёнки внизу справа и в разделе Language выберите «Русский (Beta)». На момент подготовки материала были переведены далеко не все компоненты интерфейса. Фишка LM Studio — статистика занятой ОЗУ и ресурсов ЦПУ, а ещё скорости генерации и процента потраченного контекстного окна. К тому же можно вести отдельные чаты на разные темы, как в ChatGPT и в серверной версии DeepSeek.
В стандартном режиме LM Studio забирает почти всю оперативную память (по крайней мере все 8 ГБ, что у меня есть). Чтобы продолжать пользоваться компьютером в процессе генерации, стоит нажать на значок шестерёнки в верхней панели и отключить параметр Keep Model in Memory. Скорость генерации заметно снизится, но и потребление вычислительных ресурсов упадёт радикально.
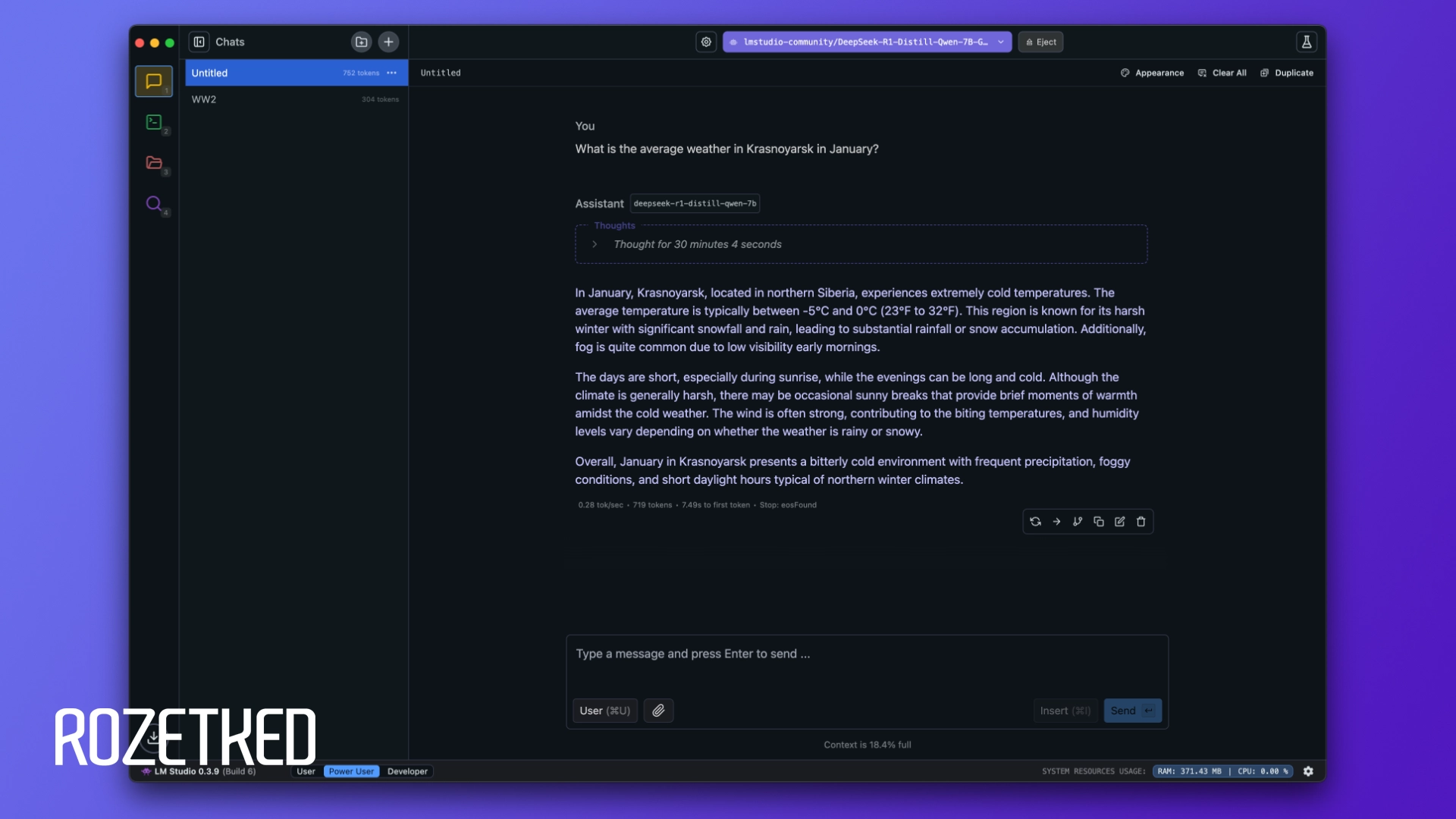
Например, на моём сетапе с отключенным параметром R1 генерировал 0,28–0,33 токена в секунду. Ответ на вопрос «Какая средняя погода в Красноярске в январе» занял у нейросети больше 40 минут (не опечатка!). На тот же вопрос веб-версия DeepSeek ответила чуть более чем за минуту. Про качество работы я не говорю: локальная модель постановила, что в самом холодном месяце в году в сибирском городе средняя температура воздуха колеблется от -5° до 0° по Цельсию. Серверная версия выдала правдоподобный диапазон (от -12°C до -20°C).
Как запустить DeepSeek локально при помощи Ollama
Ollama доступна для Windows, macOS и Linux. Приложение работает в консольном режиме — с минимум настроек, но и отвлекающих факторов. Расскажу, как настроить:
- Скачайте Ollama на свой компьютер с официального сайта и установите как обычное приложение.
- Откройте приложение «Терминал» или аналогичный консольный интерфейс.
- Запустите Ollama и пройдите первичную настройку.
- Введите ollama run deepseek-r1:7b, чтобы запустить модель на 7 млрд параметров. Для более масштабных моделей меняйте число в конце команды. И не забудьте нажать Enter, чтобы подтвердить ввод.
- Дождитесь, пока программа скачает модель с сервера. По завершении в терминале появится поле ввода запроса. Ответ появится здесь же, процесс «рассуждений» заключается в тег <think>.
- Чтобы выйти из Ollama, введите /bye. Меню справки c полным списком доступных команд открывается по команде /?.
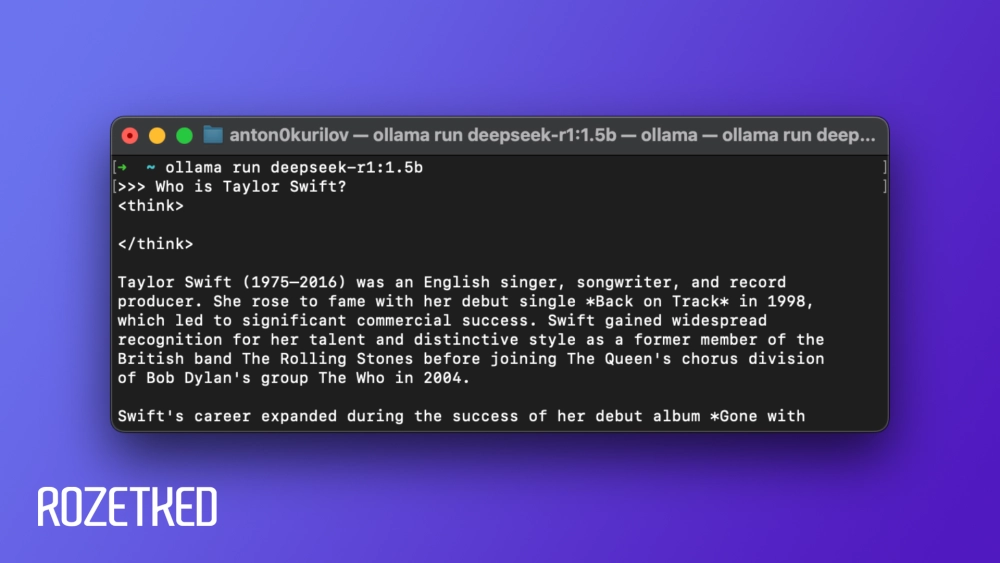
Впечатления
На MacBook Air с M1 работать даже с DeepSeek-R1 на 7 млрд параметров решительно невозможно: приходится тратить слишком много времени на ожидание ответа, да ещё и перегружать компьютер. Результат, то есть ответ чат-бота на заданный вопрос, никак вышеописанные жертвы не оправдывает. Модель на 1,5 млрд параметров работает даже быстрее, чем веб-версия, вот только качество ответов ещё ниже.
Поэтому стоит попробовать запустить более мощную модель (хотя бы на 14 млрд токенов) на хоть сколько-нибудь производительном компьютере. Ждём ваших отчётов в комментариях!