«Яндекс» опубликовал исходный код платформы для работы с большими данными YTsaurus
С ней работает большинство сервисов «Яндекса».
Компания «Яндекс» опубликовала исходный код YTsaurus — платформы для хранения и обработки больших данных, с которой работает большинство сервисов «Яндекса».
В компании описывают YTsaurus так:
«Платформа подходит для широкого круга задач, от аналитики до обучения сложных моделей с миллиардами параметров. Например, „Поиск“ строит с помощью YTsaurus поисковый индекс, а беспилотные автомобили используют платформу, чтобы обрабатывать данные о поездках и улучшать свои алгоритмы. YTsaurus управляет суперкомпьютерами „Яндекса“, распределяя нагрузку так, чтобы их вычислительные мощности использовались наиболее эффективно».
Руководитель отдела технологий распределённых вычислений «Яндекса» Максим Бабенко рассказал, что разработка YTsaurus ведётся с 2010 года. Компания начала делать собственную платформу для работы с большими данными, потому что ни одно из имевшихся на рынке решений не отвечало необходимым требованиям. На данный момент YTsaurus является одним из ключевых элементов внутренней инфраструктуры «Яндекса».
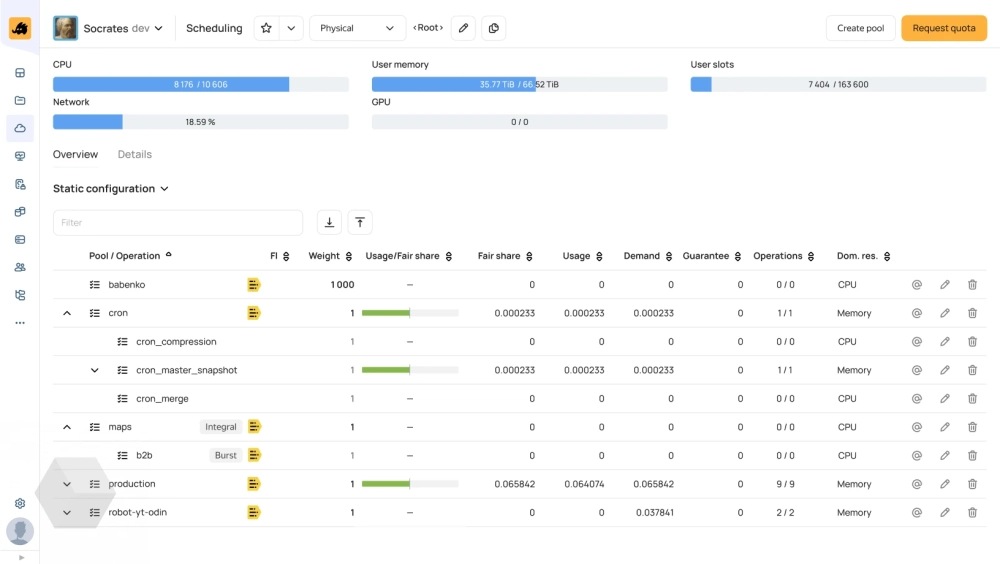
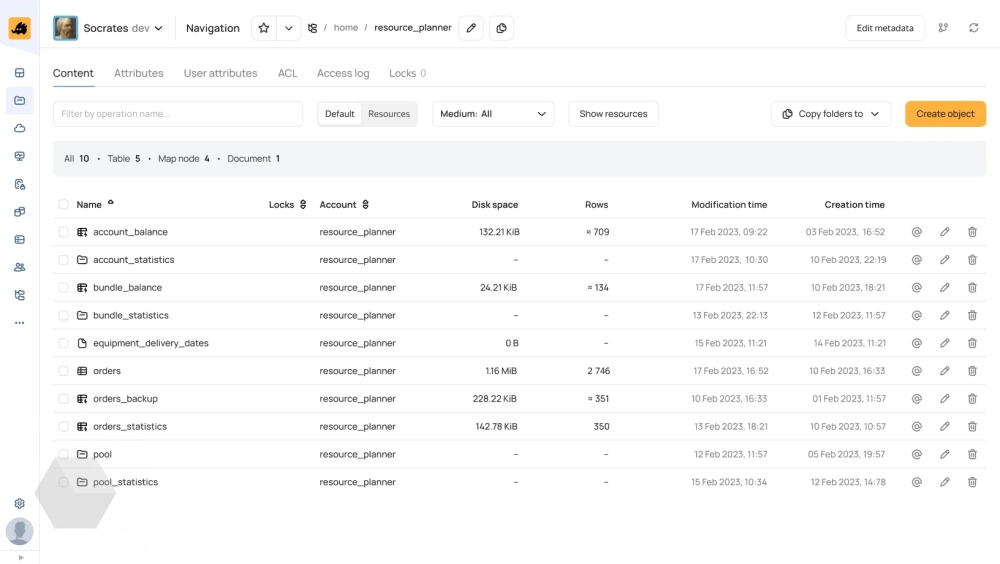
YTsaurus — отказоустойчивая и легко масштабируемая платформа. Её можно использовать как классическую MapReduce-систему, но при этом есть поддержка и других популярных подходов к обработке данных — например, есть интеграции с ClickHouse и Apache Spark.
В «Яндексе» выразили мнение, что YTsaurus принесёт наибольшую пользу крупным компаниям, которые обрабатывают гигантские объёмы данных на тысячах серверов в условиях постоянно возрастающей нагрузки. Публикация исходного кода в открытый доступ выведет платформу «на новый виток развития».
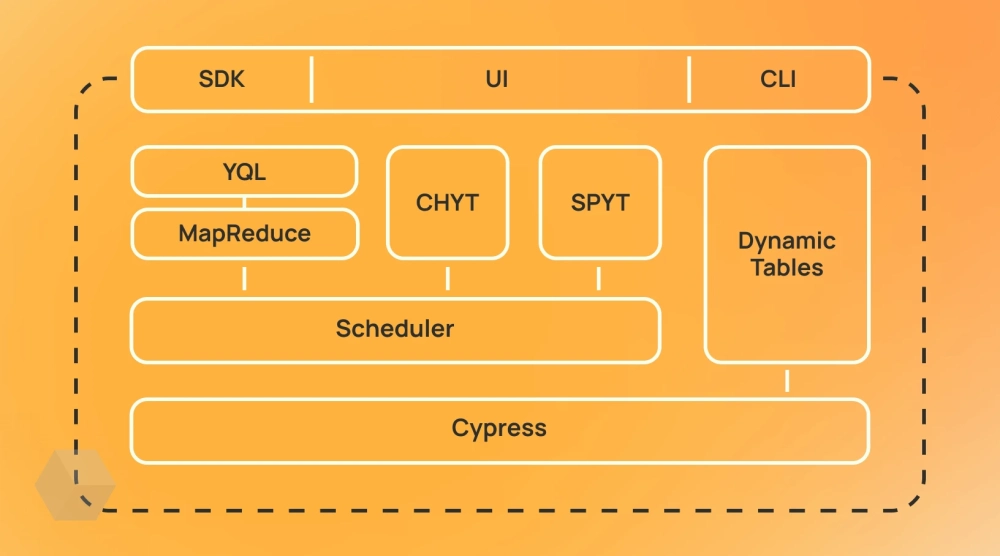
Код и документация YTsaurus доступны на GitHub. Код распространяется под лицензией Apache 2.0. Платформу можно не только свободно использовать, но и доработать под определённые нужды.