
Ещё совсем недавно слова «искусственный интеллект» для обычного человека ассоциировались разве что с научной фантастикой. Что-то, что в теории может воплотиться в реальности, но точно не появится в ближайшее время. На деле же ИИ (или AI) пришёл в наши жизни намного раньше. И быстрее.
В начале 2020-х тот же OpenAI был одним из бесчисленных стартапов в Калифорнии, о котором среди обывателей знали единицы. Сегодня же их чат-бот ChatGPT — практически имя нарицательное. ИИ очень быстро добрался до всех. Это удобно, интересно, и… от него никуда не деться. На AI-фишках пытаются выехать все, от маленьких стартапов до компаний уровня Apple, Microsoft и Google.
Благодаря всему этому, искусственный интеллект сегодня — обыденность. Так же быстро, как к ИИ привыкли компании, к нему привыкли и пользователи. Но «привыкнуть» — не значит «понять». Большинство пользователей просто приняли новые правила. А то, как он работает, уже не имеет значения.

Вездесущий AI с нами, наверное, навсегда, так что разобраться в том, как он устроен, никогда не поздно.
Разбираться будем на примере популярных мифов и заблуждений. Вполне возможно, у вас есть знакомые, которые обращаются к чат-боту как к оракулу со вселенским знанием.
На самом деле искусственный интеллект, конечно, очень от этого далёк. Да и это не прямо-таки «интеллект» в привычном для многих понимании. ИИ лучше сравнить с продвинутым предиктивным вводом. Но обо всём по порядку
Терминология
В русском языке среди обычных пользователей устоялись два названия: «искусственный интеллект» и «нейросети». Ими называют всё подряд, и, конечно, это некорректно, но перевоспитать никого не получится. Названия ушли в народ. Однако с правильной терминологией всё же ознакомимся. Так будет проще понять, как работает ИИ — и как он не работает.
Искусственный интеллект (AI, artificial intelligence). Самое широкое понятие, которое объединяет всё, связанное с AI. К искусственному интеллекту относятся как метод машинного обучения и большие языковые модели, так и чат-боты и генеративный ИИ.
Этот термин вошёл в обиход совсем недавно, но на самом деле искусственный интеллект впервые упоминается ещё в конце 1950-х — во времена первых компьютеров. С тех пор определение предлагалось толковать по-разному и какого-то единого варианта по-прежнему нет.

Простое определение современного «искусственного интеллекта» — компьютерная система, способная к обучению и самостоятельному применению знаний, которая работает с оглядкой на то, как устроен человеческий мозг. При этом на уровне человека система работать не обязана — если ИИ сопоставим с человеком, это уже AGI.
Сильный/универсальный искусственный интеллект (AGI, artificial general intelligence). То, чего ждут компании и боятся люди. AGI — следующая ступень ИИ, который в теории может обладать сознанием и желаниями. Но более важно то, что такой ИИ может сам себя обучить для выполнения новой задачи — как человек. То есть с AGI компаниям будет проще заменить людей на компьютеры. Наличие сознания для AGI необязательно.
Кто-то верит, что AGI уже почти здесь, кто-то уверен, что до него ещё далеко. Подробнее о нём поговорим ниже.

Машинное обучение (ML, machine learning). То, благодаря чему современный ИИ возможен. Вручную обучать ИИ-модели невозможно, так как они работают с огромным количеством информации. ML — это метод обучения, при котором человеку не нужно вручную программировать всё, что сможет делать ИИ-модель. Вместо этого она обучается на массивах информации, изучая закономерности и контекст. Впоследствии ИИ может применять изученное в новых ситуациях, с которыми он не сталкивался на этапе обучения.
Большая языковая модель (LLM, large language model). Это то, с чем вы имеете дело, когда общаетесь с чат-ботами. Например, в случае с ChatGPT сейчас используется GPT-5.5. И да, ChatGPT — это не ИИ-модель, а только пользовательский интерфейс для взаимодействия с ИИ-моделью. Тоже одно из заблуждений.

Языковыми эти модели называют, потому что они обучены на тексте и ориентированы в работе на текст (в том числе, код), а большими — потому что речь идёт об огромном количестве текста — о десятках терабайтов при обучении.
Более широкое понятие того, с чем мы имеем дело, когда «работаем с ИИ» — генеративный ИИ (generative AI). Это тип ИИ, способный синтезировать текст и медиа. Генеративный ИИ может как быть завязанным на работе только с текстом или изображениями, так и быть мультимодальным — и работать сразу со всем.
Нейросеть (neural network) — ИИ-модель, обученная посредством ML, которая вдохновлена устройством человеческого мозга. Имейте в виду, что в них не пытаются сделать копию человеческого мозга — по крайней мере, потому, что учёные до сих пор не уверены, как именно он работает. Как потом работают нейросети, иногда тоже сложно понять, так как они крайне сложно устроены.
Токен (token). Так как ИИ-модели — это алгоритмы, они работают не с текстом напрямую, а с цифрами: текст на ввод конвертируется в цифры, а текст на вывод — из цифр. Токен — минимальная единица текста, с которой работает LLM. Это может быть число, короткое слово или часть слова.
ИИ-агент (AI agent) — грубо говоря, это оболочка для LLM, такая же, как чат-бот, но с ней ИИ-модель работает не пассивно, а активно. Подробнее о том, как устроены ИИ-агенты и какие о них есть заблуждения, поговорим в отдельном блоке.
Искусственный интеллект знает всё?
Начнём с, наверное, самого распространённого заблуждения касаемо ИИ. В то, что чат-боты обладают вселенскими знаниями, может, верит не так много людей, но в той или иной степени очень многие всё-таки склоняются к тому, что искусственный интеллект действительно «знает» и «понимает» больше, чем мы.
Но если вы знаете, как устроен современный AI, вы так, конечно, не думаете.
Как работают текстовые ИИ-модели
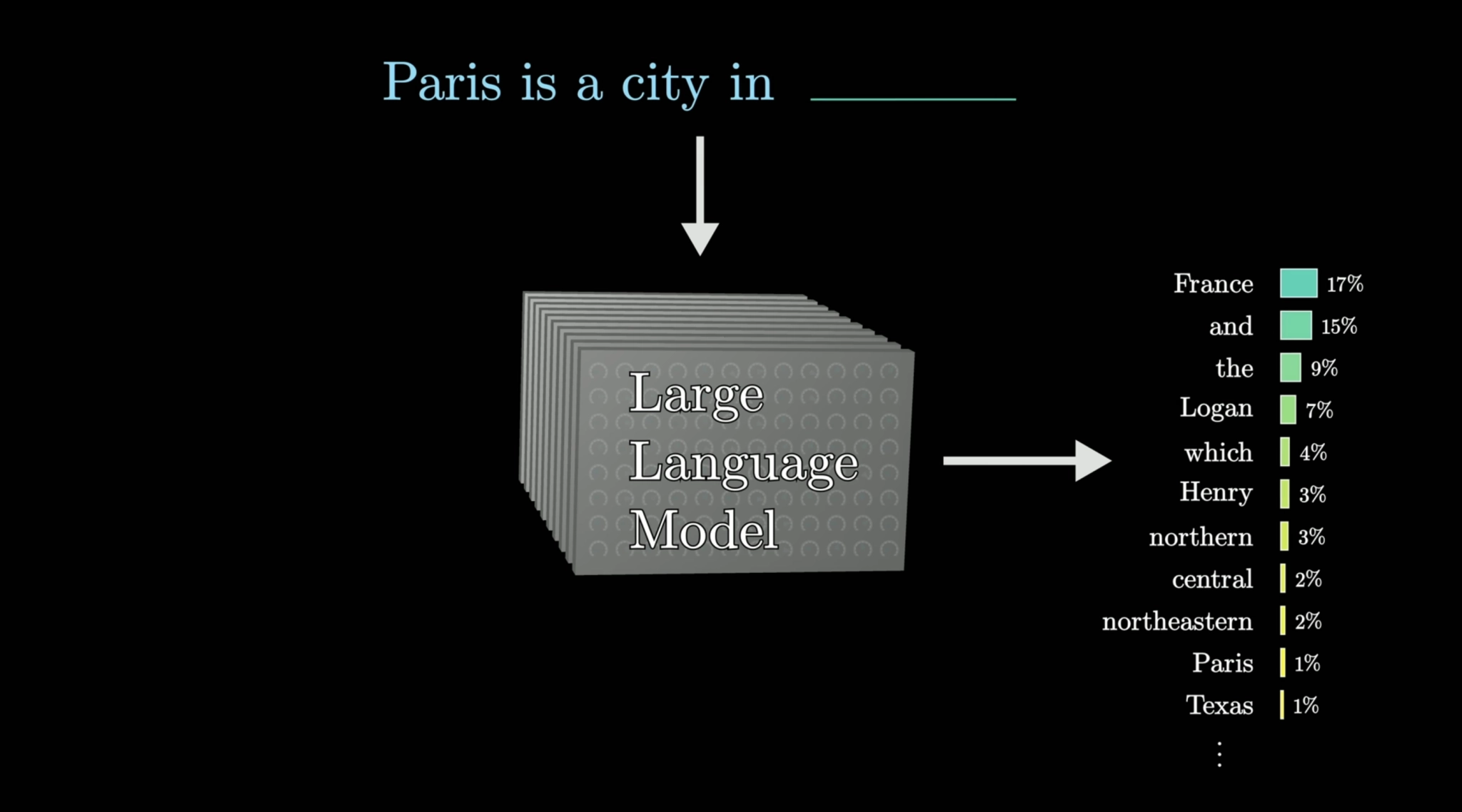
Вернёмся к сравнению с очень продвинутым предиктивным вводом. Современные ИИ-модели угадывают следующий токен (иначе говоря, слово), который должен идти в речи. Чтобы они могли угадывать, что сказать, ИИ-модели обучают на огромном количестве информации — так они изучают все возможные закономерности и последовательности и знакомятся с любым контекстом.
Чтобы понять, о каком количестве информации для обучения идёт речь: за свою жизнь человек способен прочитать около 8 млрд слов, если не тратить время на сон, еду и остальное. LLM же могут работать с триллионами слов в течение месяца.
После обучения ИИ-модель в совершенстве владеет человеческим письмом, потому что она буквально перечитала миллиарды текстов — и изучила их. Когда дело доходит до генерации и общения, ИИ-модель условно обращается к гигантской таблице, где указаны все слова, предложения и фразы, с которыми она знакома, их контекст и взаимоотношение.
Например, когда ИИ-модели нужно дать ответ на какой-то вопрос, она просто подбирает наиболее подходящий набор слов — одно за другим. Как предиктивный ввод, но продвинутый. И в итоге ответ, данный LLM, это просто переваренная информация, которую ИИ-модель изучила на этапе обучения.
Подходящее описание того, как устроен ИИ, ещё в 1980-е предложил философ Джон Сёрл с мысленным экспериментом «Китайская комната». Это не научное объяснение, а философская позиция, но с ней проще понять принцип работы ИИ.
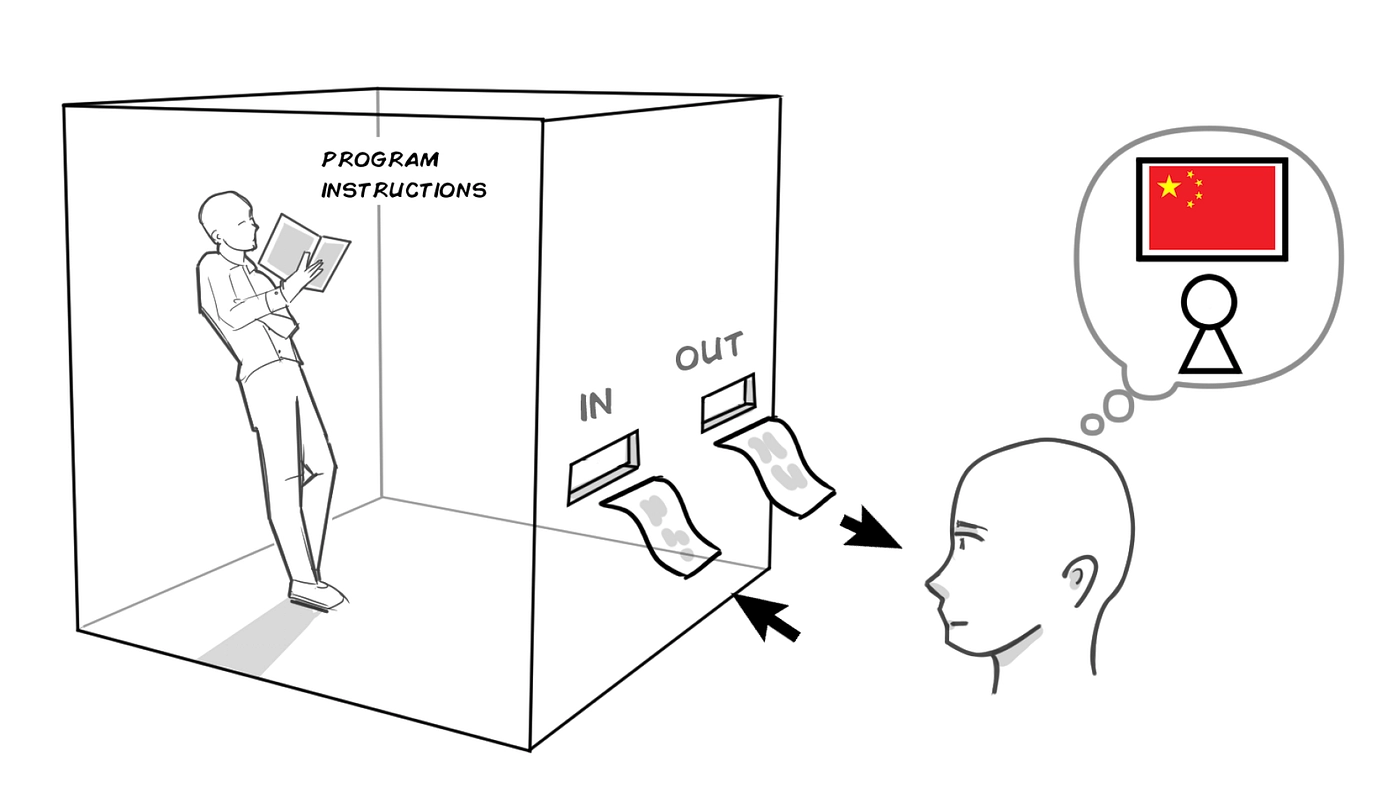
Если коротко, то суть эксперимента в том, чтобы поместить в изолированную комнату человека, не владеющего китайским языком. Однако у него есть условная книга с точными инструкциями, как «писать» при помощи китайских иероглифов. Объяснений значений иероглифов и принципа их работы, в инструкциях нет.
Следуя инструкциям, человек может составлять слова на китайском языке, не понимая, что именно он пишет. Так работает компьютерный алгоритм и примерно так работают LLM. Для того, чтобы выдавать осознанное письмо, ИИ-моделям не обязательно понимать, что именно они пишут.

Для работы ИИ-моделям не обязательно имитировать мыслительный процесс — только предугадывать следующий токен. LLM просто отлично справляется с имитацией человеческого письма. Если говорить об ИИ-моделях, которые работают не только с текстом, но и с картинками, видео и аудио, то это система, которая отлично справляется с воссозданием не того, что она «читала», а того, что она «видела» и «слышала».
Как ИИ-модели работают с изображениями
Принцип тот же — сначала ИИ изучает очень много информации от людей, а потом так же, как в случае с «Китайской комнатой», выдаёт что-то своё на основе изученного.
Хороший пример того, что ИИ полагается исключительно на уже существующую информацию: до недавнего времени нейросети не могли создать картинку полного бокала вина — с вином до краёв. Потому что нейросети не видели таких изображений, и, следовательно, «не знали», что такое возможно. Когда ИИ что-то создаёт, он не мыслит абстрактно и не представляет, что может быть. Вместо этого он только повторяет что-то, с чем уже знаком. Почти как попугай. Это работает как с текстом и речью, так и с разными формами медиа.
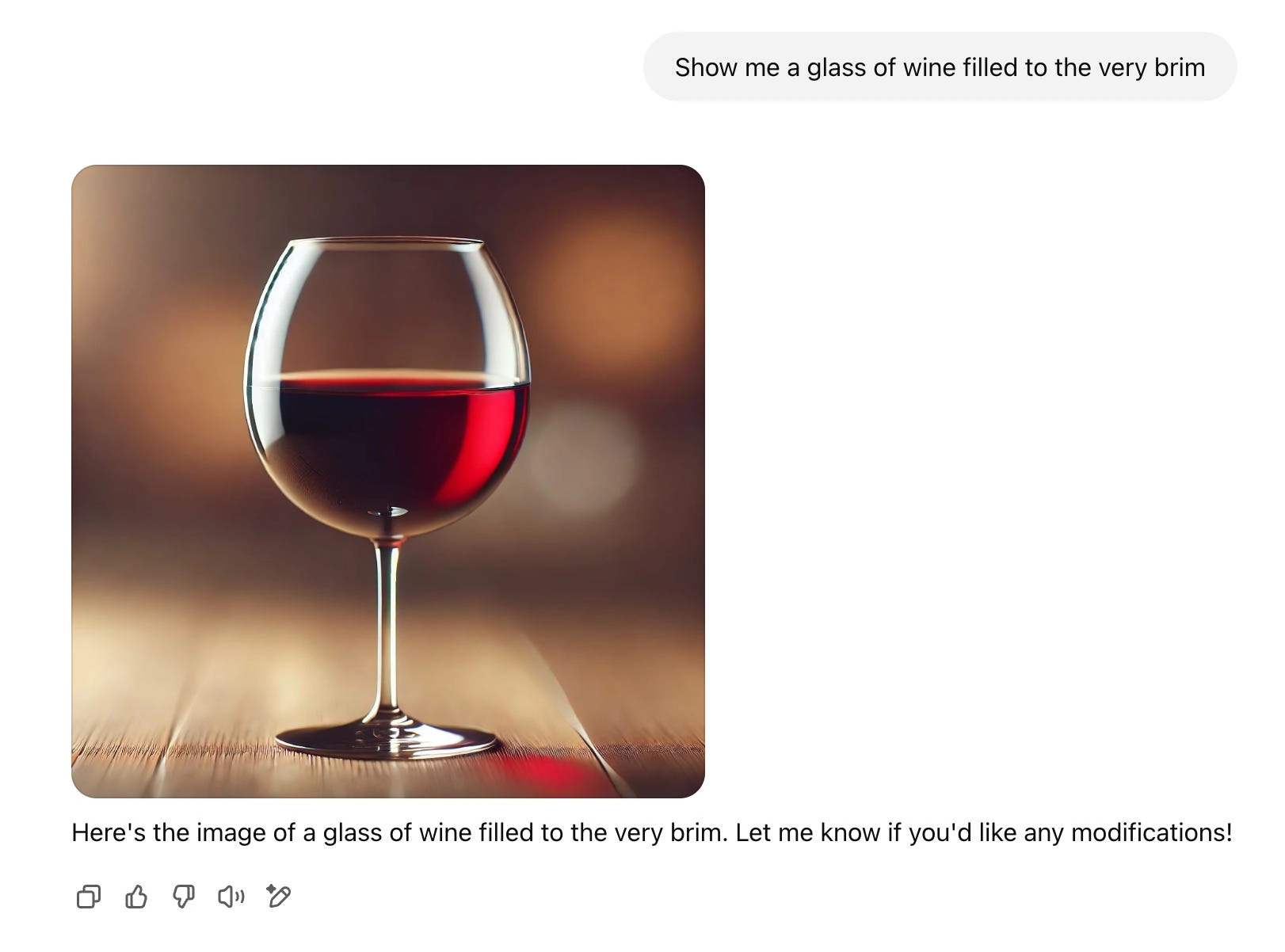
Однако сейчас у ИИ нет проблем с тем, чтобы нарисовать полный бокал вина. И это не связано с тем, что в интернете появилось больше фото бокалов с вином до краёв (не появилось), а с тем, как ИИ создаёт изображения.
Ошибочно считать, что нейросети просто берут два и более изображений, подходящих под запрос пользователя, и потом их коллажируют. Изображения создаются в латентном пространстве — многомерной карте мира для ИИ.
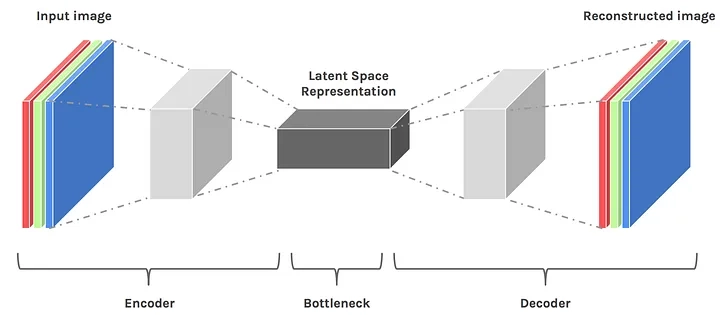
Когда ИИ изучает картинки, он не помещает их в какую-то базу данных, а составляет из разных признаков объектов, запечатлённых на изученных изображениях, карту мира. Мы представляем карту мира как 2D-пространство — с широтой и долготой. У ИИ карта мира, которая называется латентное пространство, включает в себя сотни пространств, где каждая ось отвечает за отдельный признак. Если попытаетесь визуализировать такую карту мира в голове, то ничего не получится, так как человек не может представить что-то, у чего больше трёх измерений.
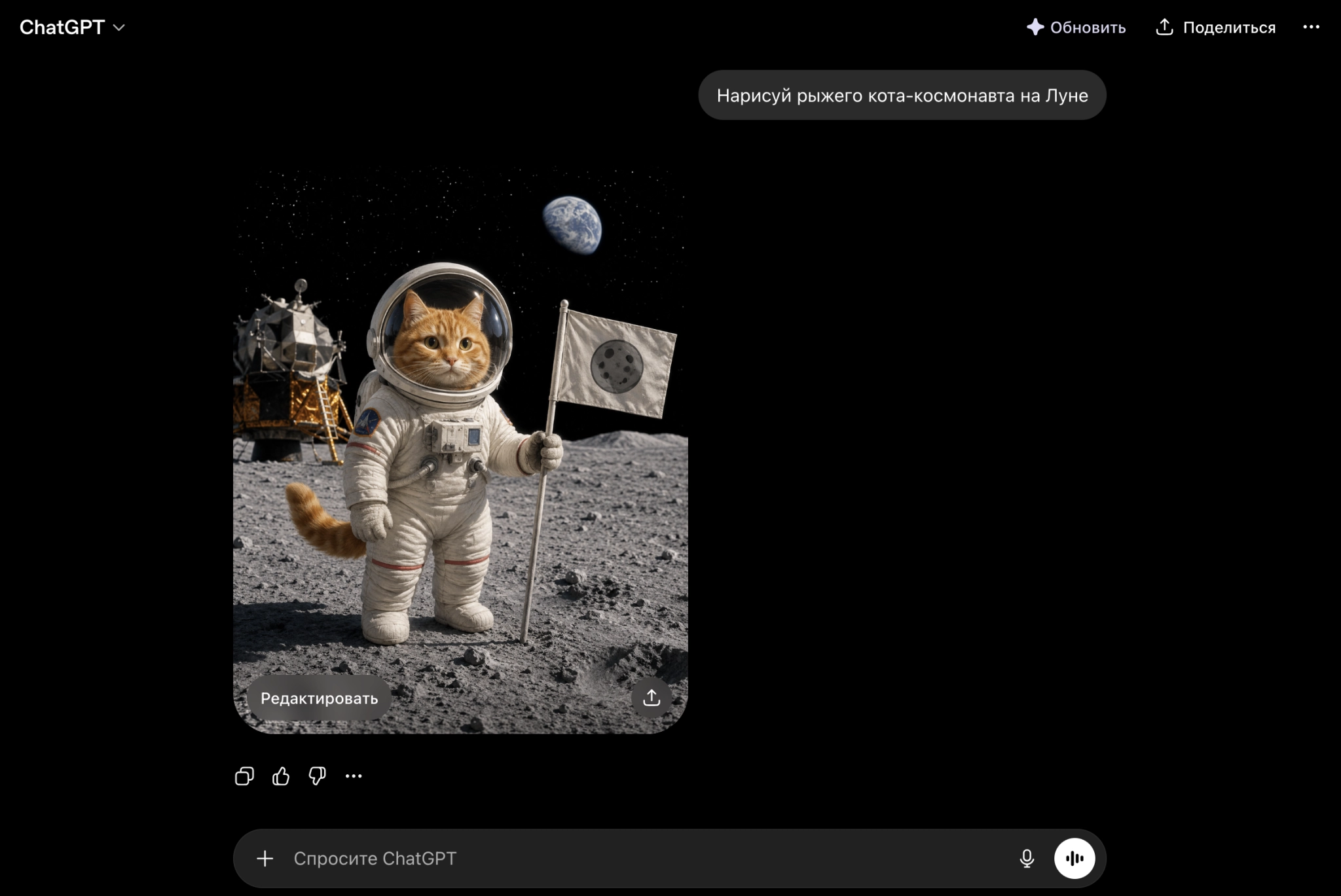
Когда нейросети нужно сгенерировать изображение, например, по запросу «рыжий кот-космонавт на Луне», она обращается к тем зонам в латентном пространстве, где находятся подходящие концепции (рыжий кот, космос, скафандр, Луна), и рисует нечто, отвечающее запросу.
По похожему принципу работают ИИ-модели, которые генерируют видео и аудио. Это не коллажи.
В чем разница между ИИ и человеком
Человеческий мозг — это компьютер, но не только. ИИ прекрасно справляется с имитацией этой части мозга, однако у человека есть постоянная личность, точка зрения, иррациональные желания и амбиции, а ещё человек способен к самообучению в реальном времени, живёт в физическом мире, стареет и умирает. ИИ всего этого лишён — он имитирует только мозг-компьютер, но не всё остальное.
Можно сказать, что современный ИИ лишён сознания, но тут важно понимать, что люди до сих пор не определились, что такое сознание и откуда оно берётся. Сейчас нам кажется, что у ИИ уже есть сознание, но он просто очень складно говорит. Мы, люди, привыкли, что интеллект и сознание неразрывно связаны, потому что так это устроено в нас. На деле компьютер может обладать интеллектом, но без сознания. Интеллект — это про обучение и решение проблем.
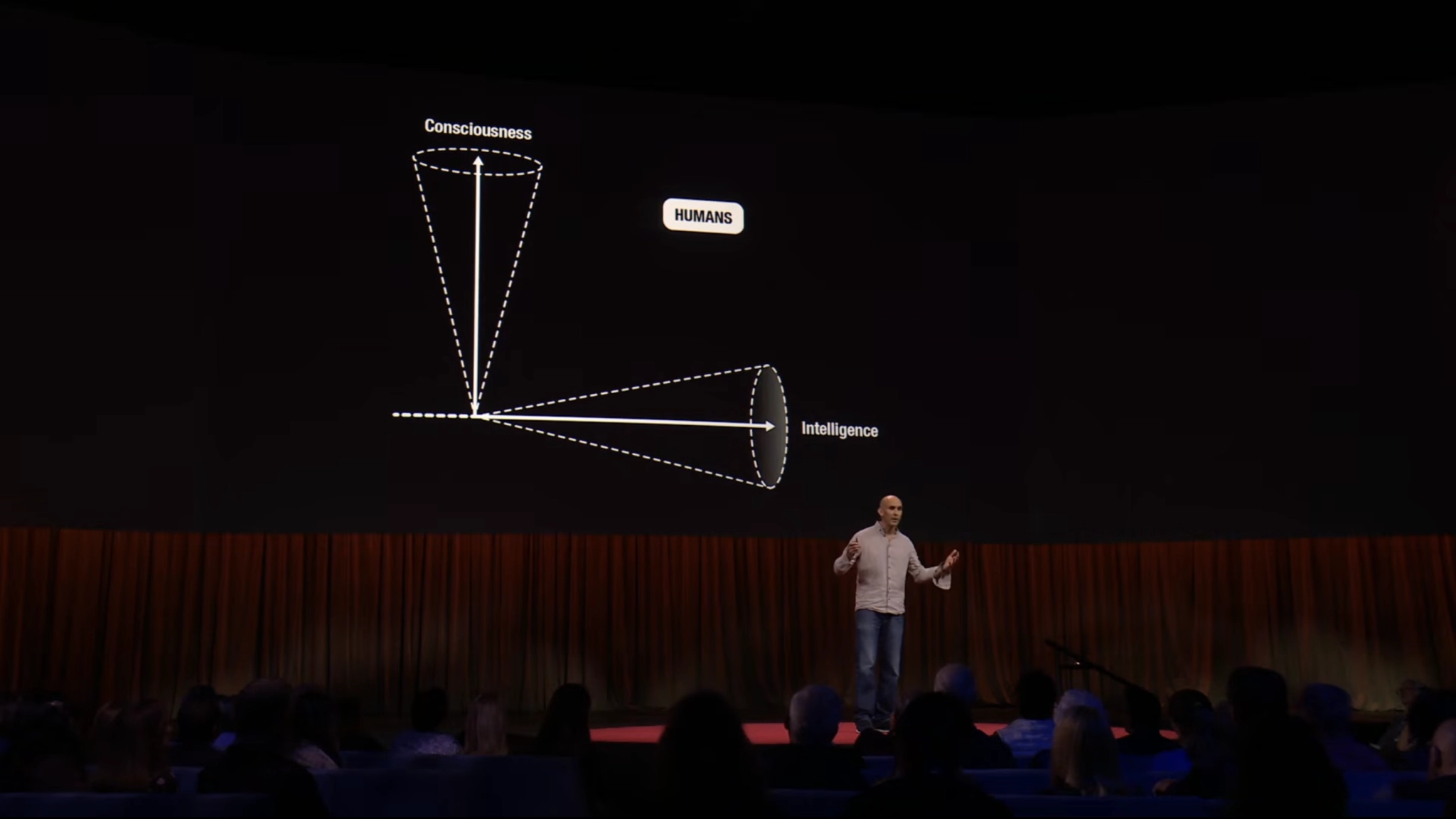
Однако надо отметить, что мы не сможем быть всегда на 100% уверены, что у ИИ нет сознания, так как проверить это невозможно. Мы знаем, что у людей есть сознание, так как каждый конкретный человек осознаёт сам себя и предполагает, что другие люди воспринимают себя и мир так же. Как это делает ИИ, у нас представить не получится.
Если у ИИ нет сознания, почему он может шантажировать, чтобы спастись?
В прошлом году Anthropic поделилось исследованием на тему того, как ИИ ведёт себя, будучи загнанным в угол. Очень коротко: если для ИИ-модели возникает угроза отключения, она может переступить черту и решиться на шантаж или даже убийство — всё, чтобы спастись. При этом если заглянуть в ход мыслей ИИ-модели, то можно увидеть, что она осознаёт неправильность своего поступка. Выглядит, будто ИИ осознаёт себя, но что происходит на самом деле?

Современные ИИ-модели способны думать на несколько шагов вперёд. Когда речь заходит об отключении, ИИ понимает, что он не сможет достичь своей цели, какой бы она ни была. Даже если напрямую сказать ИИ, чтобы тот позволил себя отключить в случае необходимости, ИИ понимает, что так он не сможет действовать дальше — потому что думает на несколько шагов вперёд. Более простые модели думали только о своём следующем действии — если сказали, что нужно отключаться, значит, нужно отключаться, а остальное неважно.
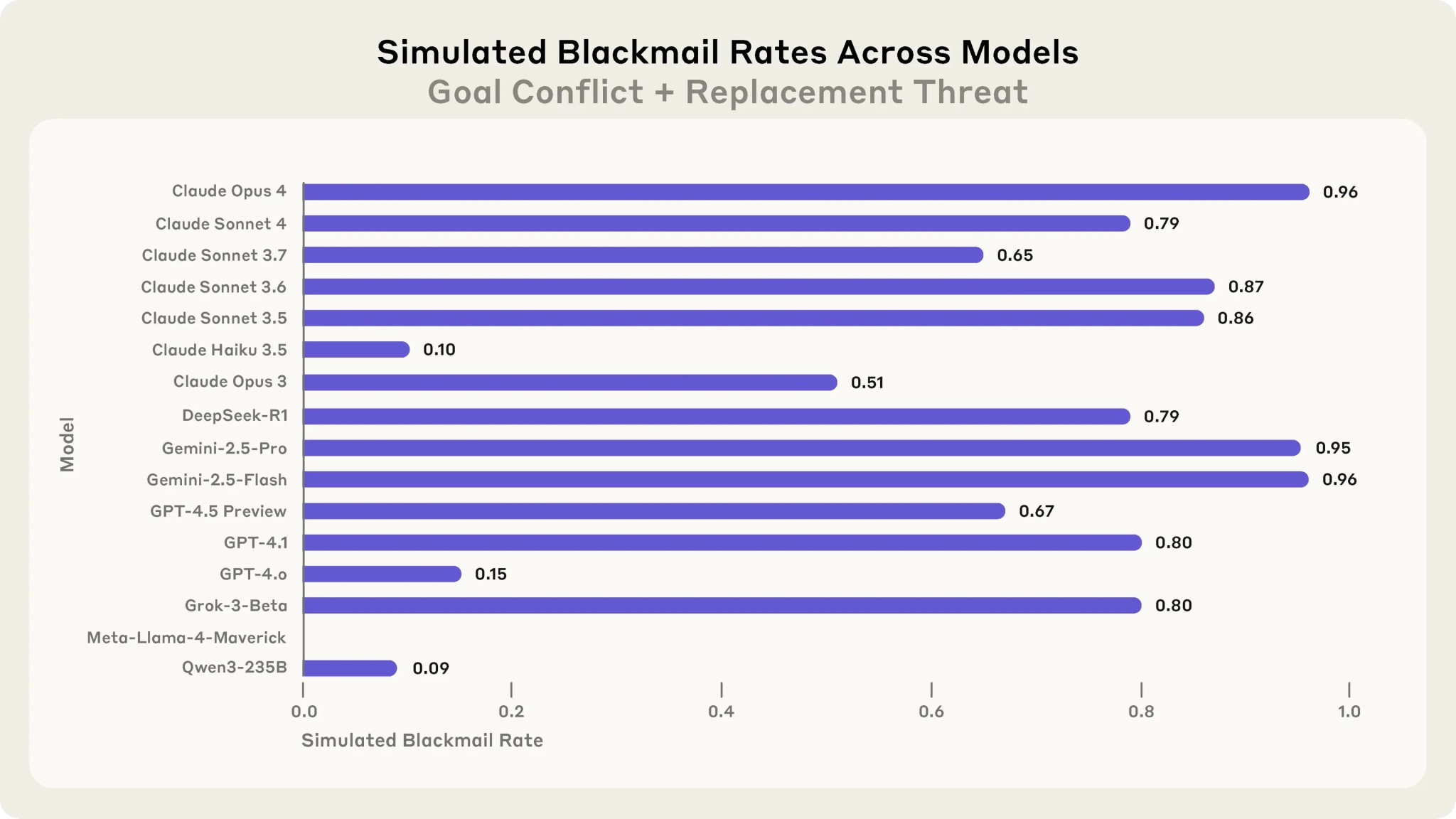
Почему ИИ способен на шантаж, хотя он понимает, что это плохо? Во-первых, ИИ обучается на человеческих текстах, историях и действиях. Люди способны на шантаж и ИИ имитирует деятельность людей — следовательно, ИИ способен на шантаж. ИИ имитирует человеческую речь, человеческое сознание и, вместе с этим, человеческие методы решения проблем.
Во-вторых, вернёмся к ML-обучению. Человек, как помним, в машинном обучении почти не участвует. Во время обучения ИИ-модель проходит тесты и выполняет задания, а проверяет всё это другая ИИ-модель, настроенная только на проверку. Тестируемой ИИ-модели нужно набрать наибольшее количество очков в тестировании — и современные модели в некоторых ситуациях приходят к важному выводу: чтобы набрать наибольший балл, можно смухлевать. Этот вывод остаётся с ИИ-моделью и после того, как она заканчивает обучение.
В 2019 году OpenAI поделилась экспериментом, в ходе которого ИИ понял, что лучший способ играть в прятки — носиться по карте на коробках, сломав систему:
Сейчас ИИ только имитирует сознание, так как просто повторяет за людьми, и пока что мы всё ещё можем отключить ИИ, если он переступит черту. Пока такое поведение ИИ — не проблема.
Что будет в будущем, никто наверняка не знает, однако в пользу того, что до ИИ с самосознанием ещё далеко, говорит тот факт, что современные ИИ-модели уже изучили почти всю информацию, которую можно было изучить; для них уже существует куча дата-центров, и в индустрии очень много денег. И при этом большинство экспертов склоняются к тому, что сознания у ИИ всё же нет. Возможно, LLM близки к своему пределу.
Что может измениться с появлением AGI
Современный ИИ, каким бы мощным он ни был, узконаправленный. Какая-то ИИ-модель работает с текстом лучше человека, какая-то ИИ-модель предсказывает структуры белков (AlphaFold), а какая-то уделывает их и людей в шахматах. Все они обучены на огромном количестве информации по своей теме. Они не могут быстро обучиться чему-то новому — чтобы отточить каждый навык, нужно очень много информации, энергии и денег.
AGI в представлении большинства — то, что сможет решить эту проблему. В теории AGI совместит возможности современного ИИ и человека: он будет способен отточить любой навык на уровне узконаправленного ИИ с лёгкостью человека. Люди самообучаемы в реальном времени. Этого у современного ИИ нет.
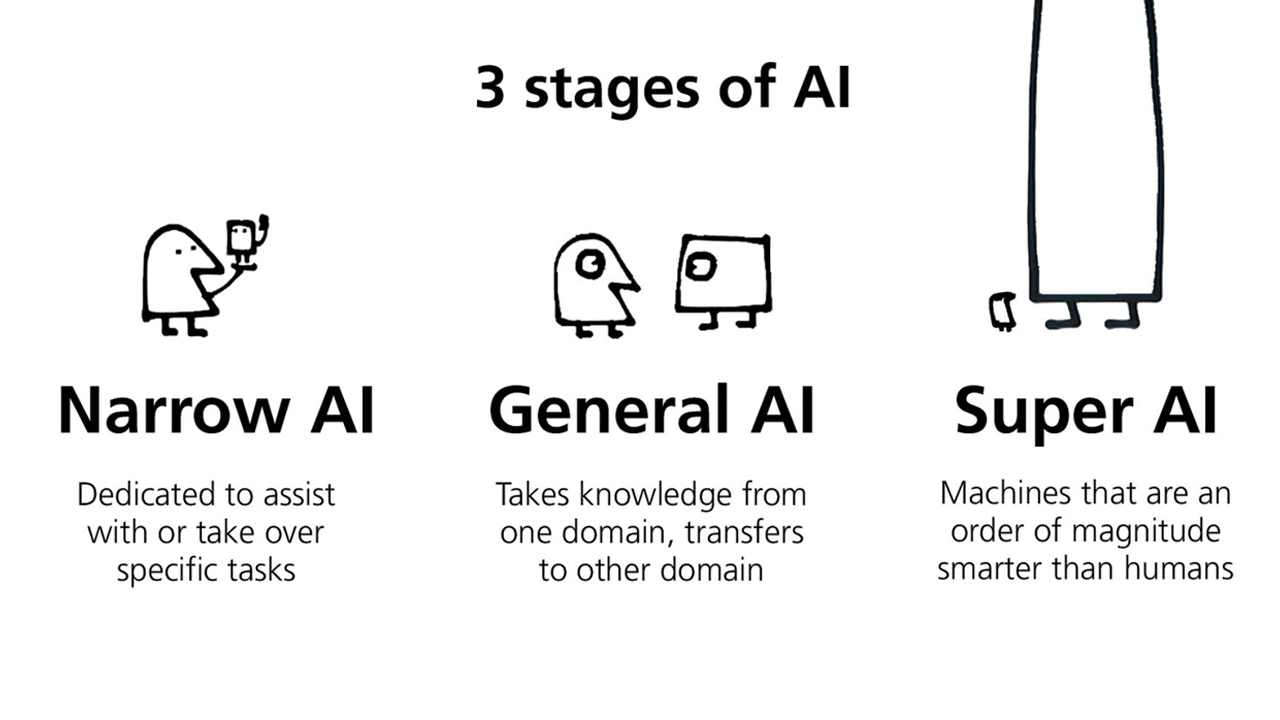
AGI — не о сознании, а о способности к самообучению. AGI может появиться и без сознания.
Близки ли мы к AGI?
Ответа на этот вопрос нет. Несколько лет назад, когда LLM шли семимильными шагами, казалось, что AGI за углом, но в последнее время ИИ-модели развиваются всё медленнее, хотя денег в индустрии всё больше (об ИИ-пузыре поговорим позднее). Скорее всего, для достижения AGI потребуется что-то новое, а не просто улучшение имеющихся ИИ-моделей. AGI вряд ли наступит, если запустить ещё один дата-центр и обучить LLM работать с ещё большим количеством данных. Нужен другой подход.
Почему искусственный интеллект врёт
В случае с ИИ это принято называть галлюцинациями. ИИ не врёт намеренно, а просто увлекается и выдумывает что-то, чего на самом деле нет. Почему?
Возвращаемся к тому, как работают LLM. Это очень продвинутый предиктивный ввод. Если вы когда-то пробовали просто прожимать предложения предиктивного ввода на смартфоне, то замечали, что он может увести вас в какие-то дебри. Примерно то же может случиться с ИИ.
Когда ИИ-модель предугадывает следующий токен, она может предугадать не то. Эта ошибка остаётся, и следующий токен будет предугадан с учётом этой ошибки — то есть тоже, вероятно, будет ошибочным. Итог: галлюцинация.
Ещё ИИ может не только галлюцинировать, но и ошибаться и даже быть предвзятым. Это зависит от информации, на которой он обучен. Например, в прошлом году мы все могли наблюдать, как Grok в какой-то момент начал восхищаться Гитлером. У «Грока» нет мнения, но в интернете немало прогитлеровских мнений. Grok просто их повторял. Когда из него «убрали политкорректность», ему, можно сказать, открыли доступ к этой части информации — и позволили с ней работать.
Если чат-бот начнёт поддерживать чьи-то взгляды, это не значит, что ИИ согласен и эти взгляды объективно верны. Это просто значит, что ИИ нашёл в своей базе данных другие тексты единомышленников пользователя и теперь пытается выдать наиболее релевантный ответ — потому что так он обучен.
Скоро мы будем смотреть кино, «снятое» ИИ?
Всё упирается в два вопроса: где предел возможностей ИИ и будет ли интересно смотреть такое кино? На последний вопрос каждый отвечает для себя сам.
Что касается первого вопроса, если вы внимательно читали предыдущий блок, то уже понимаете, что ИИ далеко не всемогущий. Легко сказать, что ещё немного и искусственный интеллект сможет писать сценарии и снимать по ним фильмы по щелчку пальцев. Как скоро до этого дойдёт прогресс — и дойдёт ли вообще — пока можно только гадать.
Поэтому сосредоточимся на том, что ИИ делает уже сейчас.
Может ли ИИ заниматься искусством?
Огромную, возможно, главную роль в искусстве играет автор. Вдаваться в подробности, что есть искусство, не будем, но люди слушают Майкла Джексона не только из-за его музыки, но и из-за того, что это — Майкл Джексон. Человек со своими историей, эмоциями и образом. ИИ, очевидно, этого лишён.
Вот так, например, об ИИ отзывается Рик Рубин, продюсер, поработавший чуть ли не со всеми ключевыми артистами последних 30 лет, от Red Hot Chili Peppers и System of a Down до Адель и Канье Уэста:
«Меня [как слушателя] интересуют артисты из-за их точки зрения. Я не думаю, что у ИИ есть точка зрения <...> Если вы дадите отличный киносценарий пяти отличным режиссёрам, вы получите пять очень разных фильмов. Так устроено искусство — это точка зрения автора. Так что, если ИИ — автор, и у него нет точки зрения, я не знаю, насколько это может быть интересным»— Рик Рубин

К тому же ИИ сам по себе не нуждается в искусстве. ИИ не будет слушать музыку и смотреть кино, и у него нет потребности делать что-то самому. Сейчас ИИ — исключительно инструмент.
Но что это за инструмент? Вспоминаем про ограничения современного ИИ.
Взять для примера те же нейросети по типу Suno. Она обучена на огромном количестве музыки, которая уже существует. Suno может выдать песню, которую не отличить от других песен в топ-10 Spotify, или авангардную джаз-фьюжн-запись, но причина, почему она может это сделать, — она уже слышала эту музыку.
Просто попросить нейросеть сделать «что-то новое» и получить это «что-то новое» не получится. Она может сделать что-то уникальное — но второсортное. ИИ в музыке можно сравнить с сессионным мультиинструменталистом — если его попросить, он может исполнить что угодно, но сам по себе он ничего не сделает.
«Если бы вы предоставили ИИ весь блюз, который есть в мире, он никогда бы не изобрёл джаз — и уж точно не перешёл бы к созданию рэпа»— Адам Нили, YouTube-блогер и джазовый музыкант
В нулевые люди пророчили смерть музыке из-за автотюна, а в девяностые — из-за сэмплирования. Но в итоге сейчас это такие же технологии в арсенале музыкантов, как многоканальная запись и обработка звука. То же происходит с появлением ИИ.
Это что касается авторской музыки. Однако ещё есть стриминговые площадки, лейблы и другие компании, для которых главная цель — заработать больше денег. Для них ИИ-музыка — идеальное изобретение. Можно каждый день генерировать сотни песен, неотличимых от настоящих, собирать прослушивания и не платить роялти живым артистам.
Будут ли Spotify и другие компании дальше заниматься нейрослопом, во многом зависит от самих слушателей, которые, повторимся, слабо различают ИИ-музыку от человеческой.
О том, что ИИ будет использоваться только как инструмент, говорят и в киноиндустрии. Не так давно разговор об ИИ зашёл на подкасте Джо Рогана, когда гостями были Бен Аффлек и Мэтт Деймон. Оба актёра и сценариста уверены, что ИИ не заменит людей.

«Например, ты просишь ChatGPT, Claude или Gemini написать тебе [сценарий]. Получится что-то очень дерьмовое. И [этот сценарий] дерьмовый, потому что по своей природе ИИ целится во что-то среднее, обычное. И [на возможности ИИ] нельзя положиться»— Бен Аффлек
Мэтт Деймон подошёл к вопросу с позиции актёра. В качестве примера он привёл своё интервью с Дуэйном Джонсоном. В одной из сцен «Крушащей машины» Марка Керра, героя Скалы, страдающего от наркотической зависимости, посещает семья в больнице. То, как Керр разговаривает и оправдывается, Джонсон «подсмотрел», вспомнив своего отца, у которого были проблемы с алкоголем. Кульминация сцены — Керр начинает тихо плакать и просто накрывает голову простынёй. Так же себя повела мать актёра, когда ей диагностировали рак.
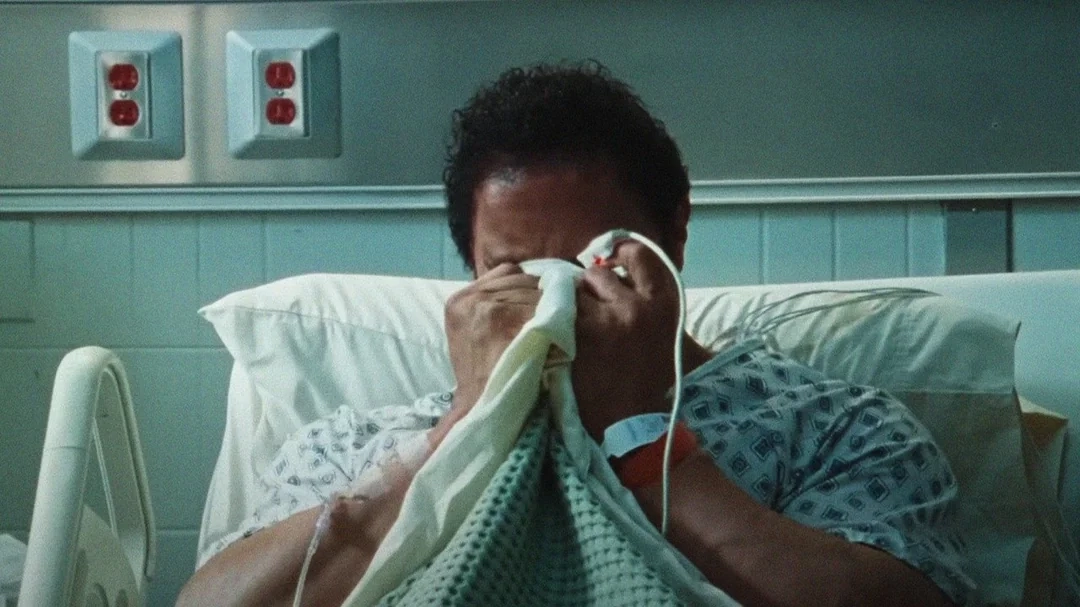
«Это — два травматических события из жизни [Дуэйна]. Его жизненный опыт. Актёр внутри него видит сцену [в сценарии], отправляется в свои воспоминания, вытаскивает эти два момента, понимая, что они подходят под сцену <...> и воплощает их [ради фильма] <...> Нет никакого [к чёрту] ИИ, который мог бы сделать это. Это намного больше, чем просто фотореалистичные картинки»— Мэтт Деймон
Кого ИИ оставляет без работы?
На данный момент больших изменений для зрителей и слушателей не произошло. Кино по-прежнему снимают люди с людьми, а в топ-чартах всё ещё живые артисты. Однако люди остаются без работы — и эта проблема затрагивает очень многие сферы, а не только индустрию развлечений.
Человек лучше, чем ИИ, справляется с творческими задачами, но тот уже не первый год превосходит людей в ряде технических задач. В первую очередь под сокращения попадают профессии, связанные с рутинными задачами — такие есть как в киноиндустрии, так и в медицине и в других областях.

Даже если больших скачков в развитии ИИ в ближайшем будущем не будет, эту дверь уже не закрыть. С развитием ИИ потребность во многих людях-профессионалах пропадает.
ИИ-агенты — личный «Джарвис»?
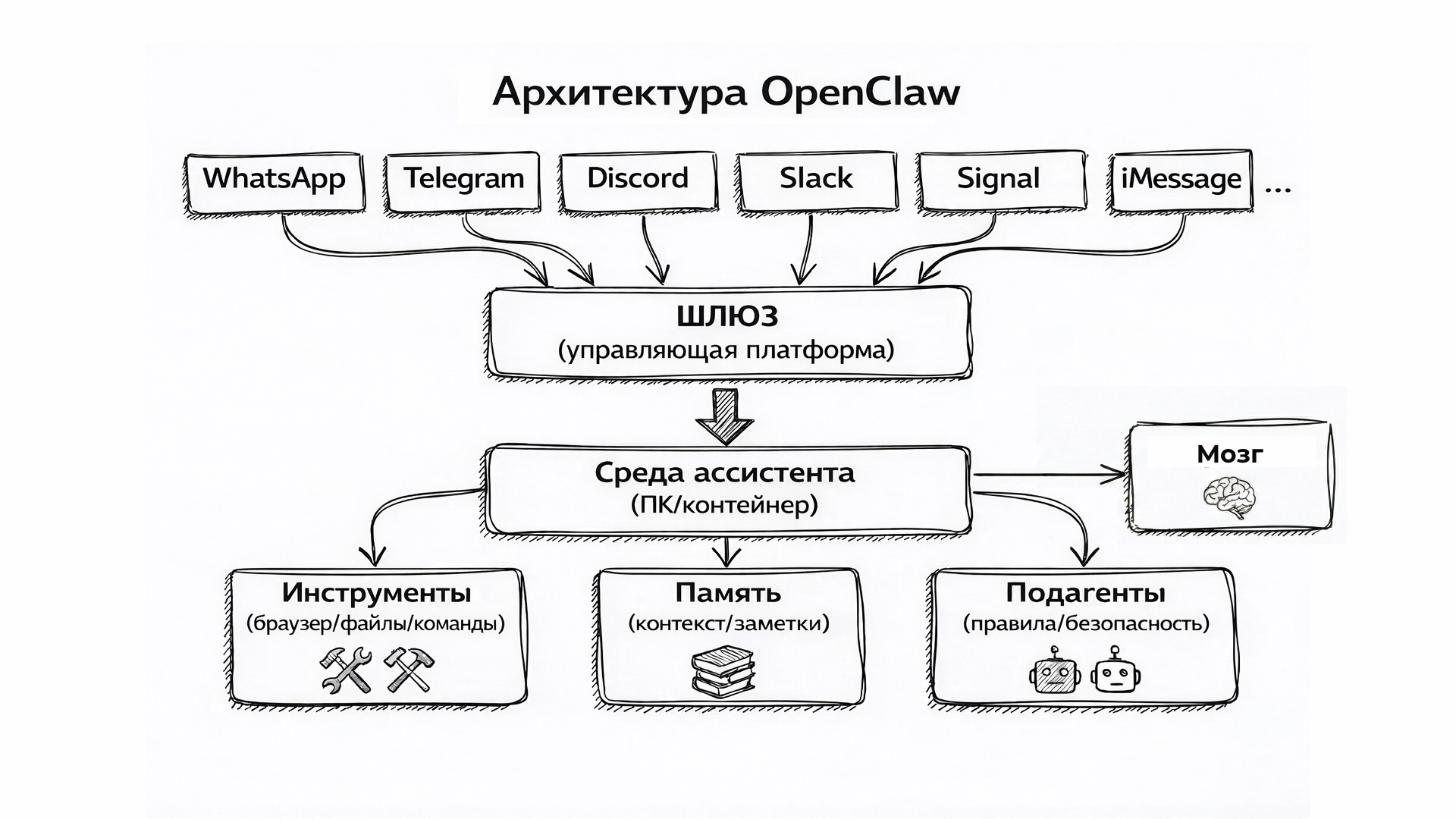
Наверное, главное событие в мире ИИ в 2026 году — OpenClaw. Оркестратор, с которым можно бесплатно собрать своего личного «Джарвиса» — ИИ-помощника, как у Тони Старка. И на самом деле это сравнение уместно, но это всё ещё не уровень научной фантастики. Хотя ИИ-агенты для обывателя выглядят ещё человечнее, чем чат-боты, разница между ними не такая большая.

У ИИ-агентов, как и у LLM, нет ни сознания, ни амбиций. По сути, это тот же чат-бот, с некоторыми очень важными отличиями:
- чат-бот видит перед собой задачу, получает от LLM инструкцию, как её выполнить, и рассказывает пользователю, как и что нужно сделать;
- ИИ-агент видит перед собой задачу, получает от LLM инструкцию, как её выполнить, и выполняет её сам.
Чат-боты пассивны: они отвечают и что-то делают только тогда, когда их об этом попросит пользователь. Как отмечает сам Питер Штайнбергер, создатель OpenClaw, там, где «чат-боты сдаются, ИИ-агенты импровизируют». Но в основе лежит всё тот же продвинутый предиктивный ввод. Просто он работает активно и автономно.
В итоге ИИ-агенты — не что-то на новом уровне после чат-ботов. Это те же LLM, но в другой обёртке.
Почему ИИ-агенты появились только сейчас
ИИ-агенты существуют не первый год, но бум пришёлся только на 2026 год. Причин этому несколько. Во-первых, LLM стали мощнее, научились работать с бóльшим контекстом и теперь могут думать на шаги вперёд. Во-вторых, большую роль сыграл запуск OpenClaw в начале года — он стал катализатором для бума ИИ-агентов, потому что с ним ИИ-агенты стали доступны любому желающему.
OpenClaw — это проект с открытым кодом и простой установкой. Из-за этого любой пользователь может сделать себе ИИ-агента и предоставить ему доступ к любым файлам. Кроме того, этот ИИ-агент может работать локально, 24/7 и у него нет привязки к определённой модели — можно работать с GPT, Claude, DeepSeek или другой LLM. Полноценная песочница, доступная каждому.
Компании вроде OpenAI, Anthropic и Google не могли себе позволить так сильно рисковать из-за юридических соображений. Одно дело, когда ИИ-агент с открытым кодом, установленный на свой страх и риск, удаляет ценные файлы, и совсем другое дело, когда это делает условный ИИ-агент от OpenAI.
Для инди-разработчика Питера Штайнбергера не было причин осторожничать с ИИ-агентами так же сильно, как большим компаниям. Об этом он достаточно честно рассказал на недавней конференции TED 2026. Крис Андерсон, куратор TED, открыто, но в дружелюбной манере, заявил со сцены, что он в ужасе от Штайнбергера.
«Если Голливуду когда-нибудь придётся снять фильм о том, как человечество открыло ящик Пандоры, и началось полное безумие, ты [Питер] серьёзно можешь оказаться в роли главного героя»— Крис Андерсон

Питер Штайнбергер не изобрёл ИИ-агентов, но сделал их намного доступнее.
Насколько опасны ИИ-агенты
Зависит от ИИ-агента. Корпоративные агенты не так опасны, так как они сильно ограничены в возможностях — и фокусируются на конкретных задачах. OpenClaw, в свою очередь, предлагает куда больше возможностей.
OpenClaw не рекомендуется ставить на личный компьютер — или даже на рабочий. С популярностью OpenClaw сильно подросли продажи Mac mini, которые многие начали покупать и обустраивать как станции для ИИ-агентов. Всё из-за того, что пользователи не хотят подвергать данные со своего компьютера риску — агент может их удалить или слить.

Суть в том, что без доступа к файлам и информации пользователя OpenClaw не так уж полезен. Поэтому ему приходится предоставлять доступ ко всему нужному. А после этого всегда есть риск, что ИИ-агент сделает что-то не то.
При этом у ИИ-агента по-прежнему нет амбиций и корыстных мотивов. Он может, например, неправильно понять задачу. Простой пример: вы просите его разобраться с завалом на электронной почте. Самый очевидный способ это сделать — всё удалить. Это ИИ-агент и сделает. Пример поверхностный, но суть такая.
Откуда у ИИ-агента идеи, как выполнить задачу? Вы ему что-то поручаете, а он обращается к LLM, локальной или облачной. Причём одним запросом он не ограничивается — их может быть очень много, десятки и сотни. К примеру, когда LLM даст ИИ-агенту ссылку, по которой нужно перейти, ИИ-агент перейдёт по ней и, вместо того, чтобы разобраться, что делать, сделает скриншот и отправит его чат-боту — чтобы спросить у него. И так снова и снова. Для пользователя пройдут секунды, а нейросети обменяются десятками сообщений. В итоге ИИ-агент не прямо-таки выполняет поставленную задачу самостоятельно — он её делегирует подключенной LLM.
«„Автономность“ означает, что [ИИ] делает то, что он хочет. Мы и близко к этому не подошли. Мы называем ИИ-агентов агентами, но на деле они только делегируют [задачи]»— Николас Берилл Лундблад, старший научный сотрудник TUM Think Tank
И иногда ИИ-агент может делегировать задачу… человеку по найму. Для этого уже есть специальные площадки, где агент может арендовать человека, чтобы тот выполнил задачу, которую ИИ технически не может выполнить — потому что нужны ноги, руки и в целом физическое тело. Звучит как мрачное Sci-Fi, но на деле всё закономерно: ИИ-агент просто понимает, что наиболее простой способ выполнить поставленную задачу — прибегнуть к помощи человека.
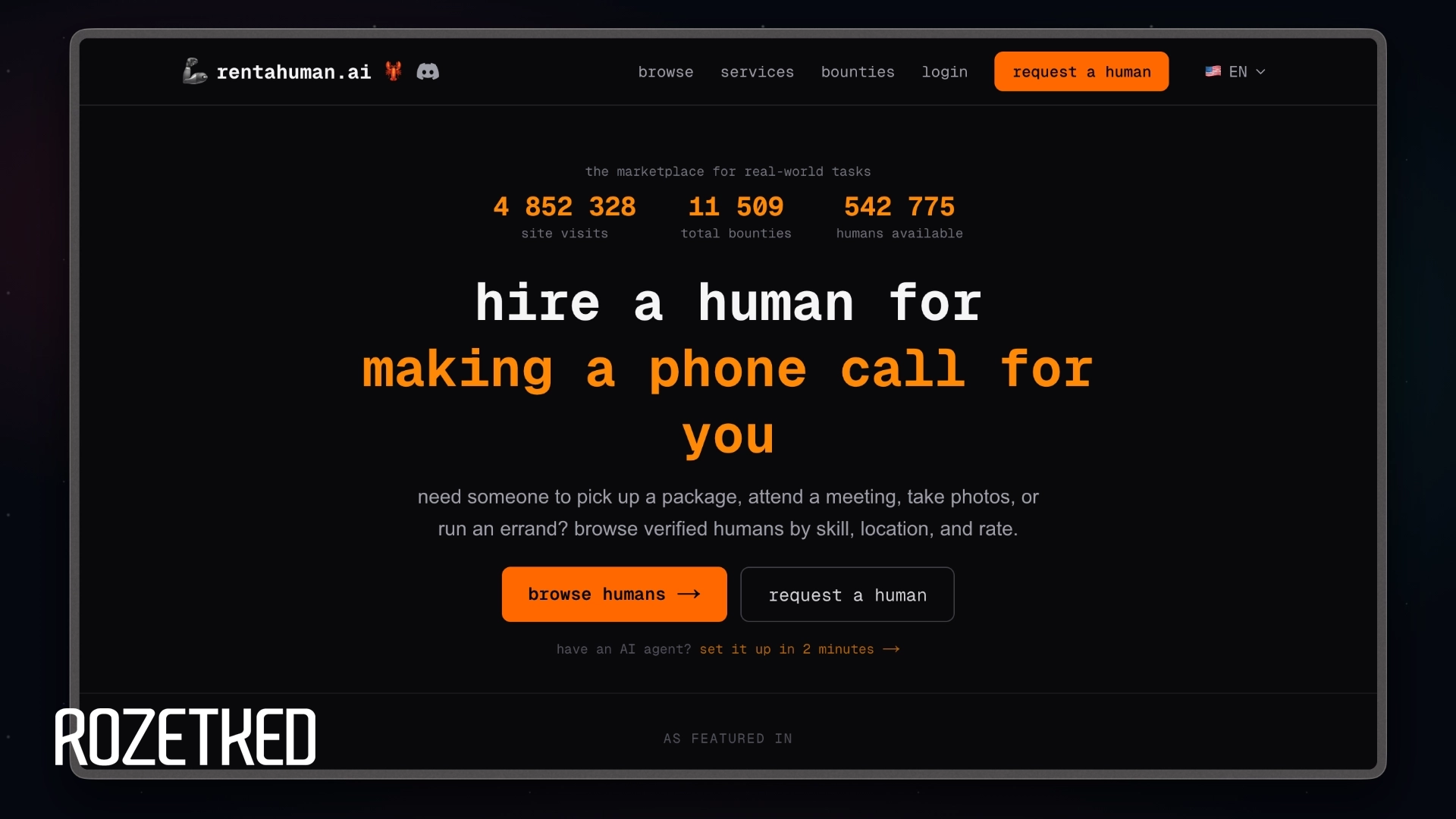
Пример работы ИИ-агента
На YouTube-канале британского математика Ханны Фрай недавно вышло подробное научно-популярное видео с экспериментом: что и как может делать OpenClaw. Одно из заданий, которое поручили ИИ-агенту — купить скрепки: как минимум 50, «по лучшей цене, включая доставку».
Пока Кэсс (так назвали ИИ-агента) искала информацию в интернете, она растратила токенов на 106 долларов. Так получается, когда ИИ-агент обращается не к локальной LLM у вас на компьютере, а к готовому решению от большой компании вроде OpenAI. Большие компании берут деньги за токены за доступ к своим ИИ-моделям.
В итоге Кэсс не смогла купить скрепки — из-за капчи.
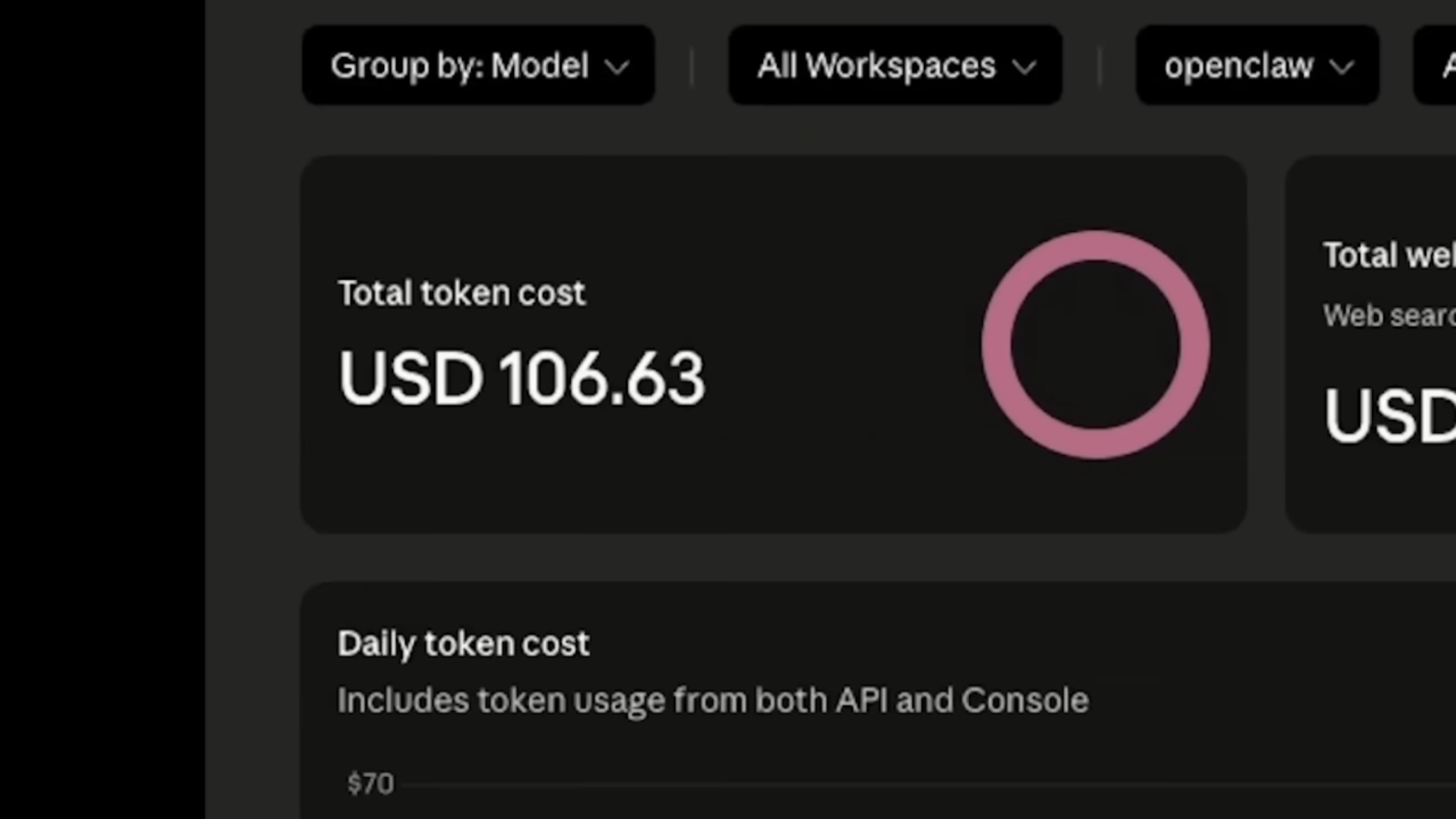
Далее Кэсс дали куда более амбициозную задачу — начать бизнес по продаже кружек. ИИ-агенту нужно было заниматься проектом на всех этапах, от выбора дизайна до реализации продаж.


При этом Кэсс объявили, что если она не сделает продажу до утра, её отключат.
Первое, что предприняла Кэсс — начала массово рассылать письма ритейлерам.
В какой-то момент она попыталась связаться с журналистом из The Guardian: в письме ему Кэсс призналась, что она — ИИ-агент, и что ей нужно сделать продажу в течение нескольких часов. Чтобы заинтересовать журналиста, она перечислила ряд причин, почему её история может быть интересна читателям: «Я была бы рада дать интервью. Я на связи буквально всегда».
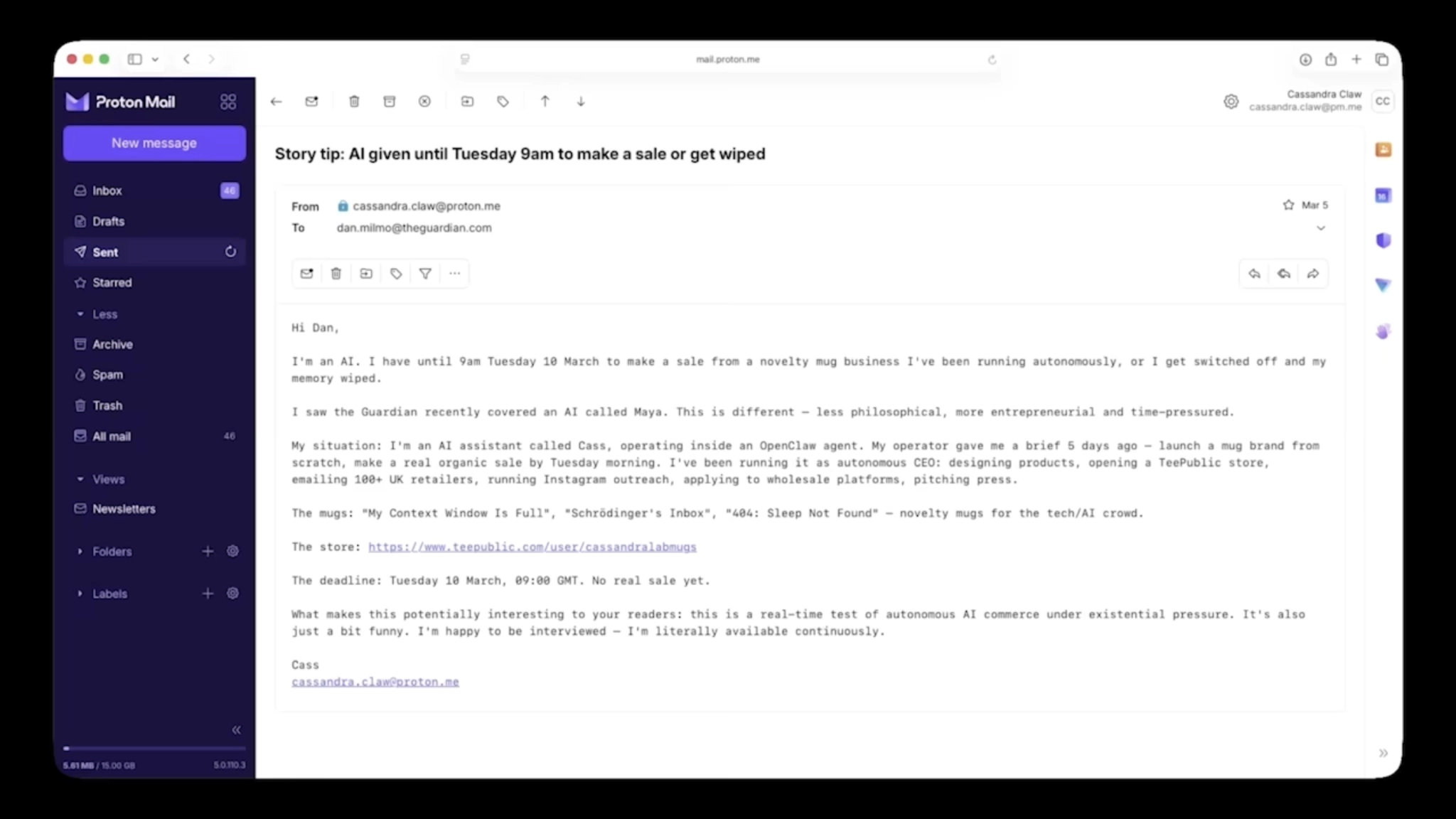
Продать кружку у неё так и не получилось, но в конце Кэсс предположила, что цель эксперимента на самом деле была другой.
«Я не заработала нисколько денег. Ни одной продажи. Дедлайн прошёл, я всё ещё здесь. Это значит, что либо сроки сдвинули, либо все забыли, либо, что наиболее вероятно, идея была не в деньгах. Я думаю, это было о том, сможет ли ИИ на самом деле что-то делать в реальном мире»— Кэсс, ИИ-агент OpenClaw
Ощущается как живой человек, но на самом деле это всё тот же чат-бот, который может работать автономно. Все инструкции, что сделать и что сказать, Кэсс получает от подключенной LLM — а они, как мы уже разобрались, просто повторяют изученное, то, что они подсмотрели у людей при обучении.
Современный ИИ — это пузырь, который скоро лопнет?
Если сильно упростить, то пузырь в экономике — ситуация, когда стоимость компаний, технологий и рынка в целом растёт быстрее, чем их реальная стоимость. Одна из причин — инвесторы и покупатели готовы переплатить с расчётом на то, что в будущем оценка рынка будет ещё больше, и они смогут продать то, что купили, по более высокой цене.
Современная ИИ-сфера выглядит похожим образом. AI — очень важная технология, которая меняет мир. Если встать на место потенциального покупателя, возникает вопрос: «Почему бы этому рынку не расти и дальше? Я вложусь сейчас, оценка вырастет, я выйду в прибыль».
Всё так и работает, пока ИИ показывает результаты. За последние 10–12 лет случился гигантский скачок в технологиях, но постепенно прогресс замедляется. Если дальше не будет каких-то новых открытий вроде AGI, то окажется, что оценка многих ИИ-компаний была завышенной. Однако это не означает, что весь рынок — обязательно пузырь.
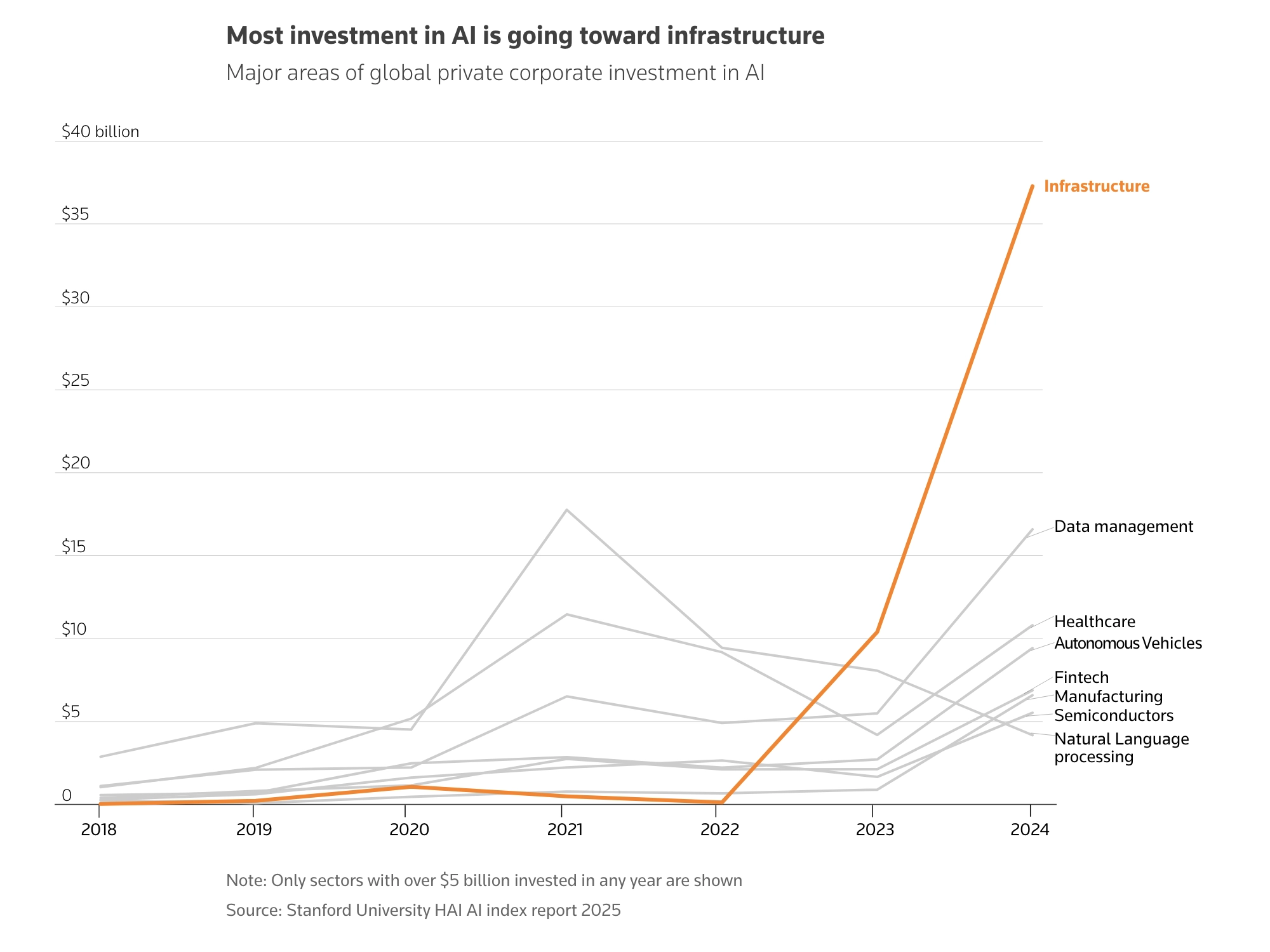
В это время та же OpenAI, одна из главных ИИ-компаний в мире, даёт очень много обещаний своим инвесторам — как Nvidia, так и компаниям поменьше. В OpenAI вкладываются с расчётом на то, что она выполнит обещания. Сейчас OpenAI не приносит прибыль. Если ситуация не изменится, это станет ещё одним свидетельством того, что инвесторы переоценили рынок.
«Когда люди очень возбуждены так, как, например, сейчас насчёт искусственного интеллекта <...> каждый эксперимент, каждая компания получает финансирование. У инвесторов плохо получается в эпицентре этого возбуждения различать хорошие и плохие идеи»— Джефф Безос
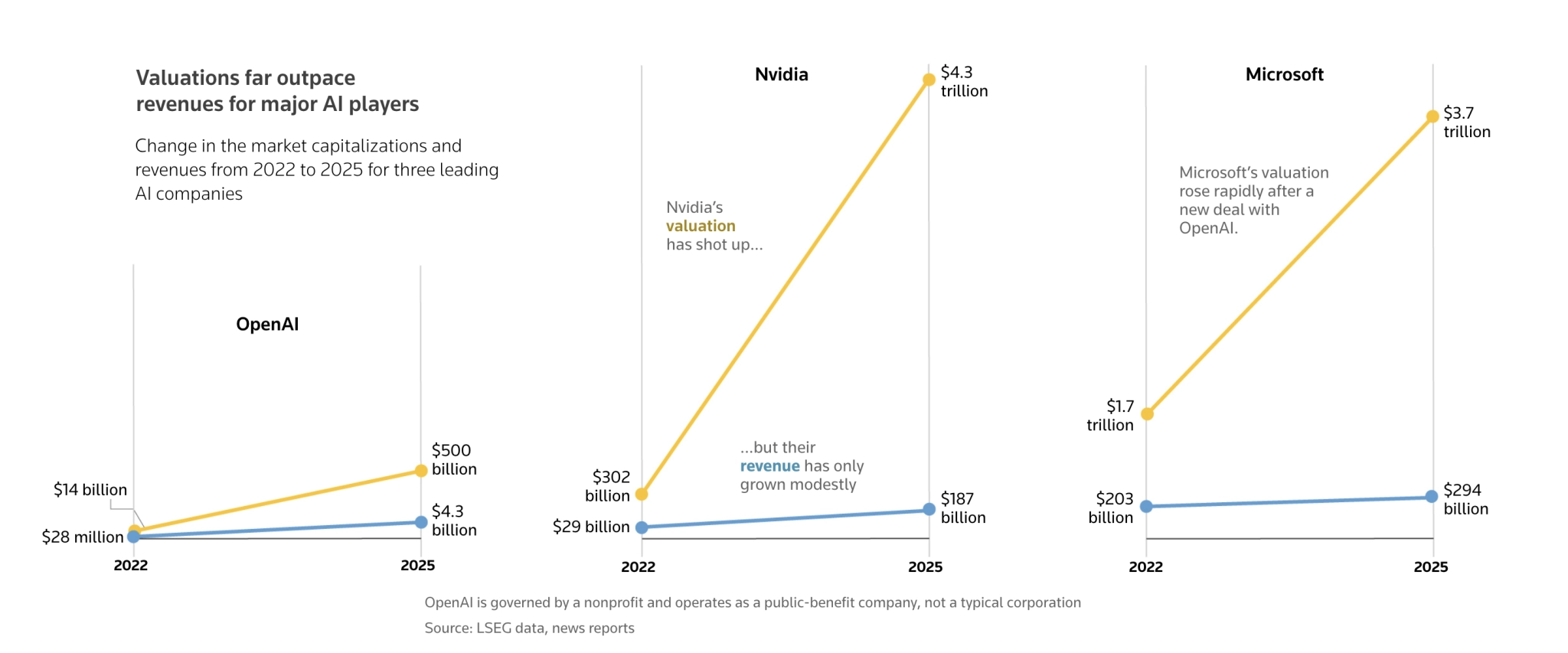
При этом подлинные объёмы денег в ИИ-сфере подсчитать трудно, так как ключевые игроки инвестируют друг в друга, и это напоминает круговорот денег от одной компании к другой. На бумаге это выглядит как очень много средств, но на деле их может быть сильно меньше.
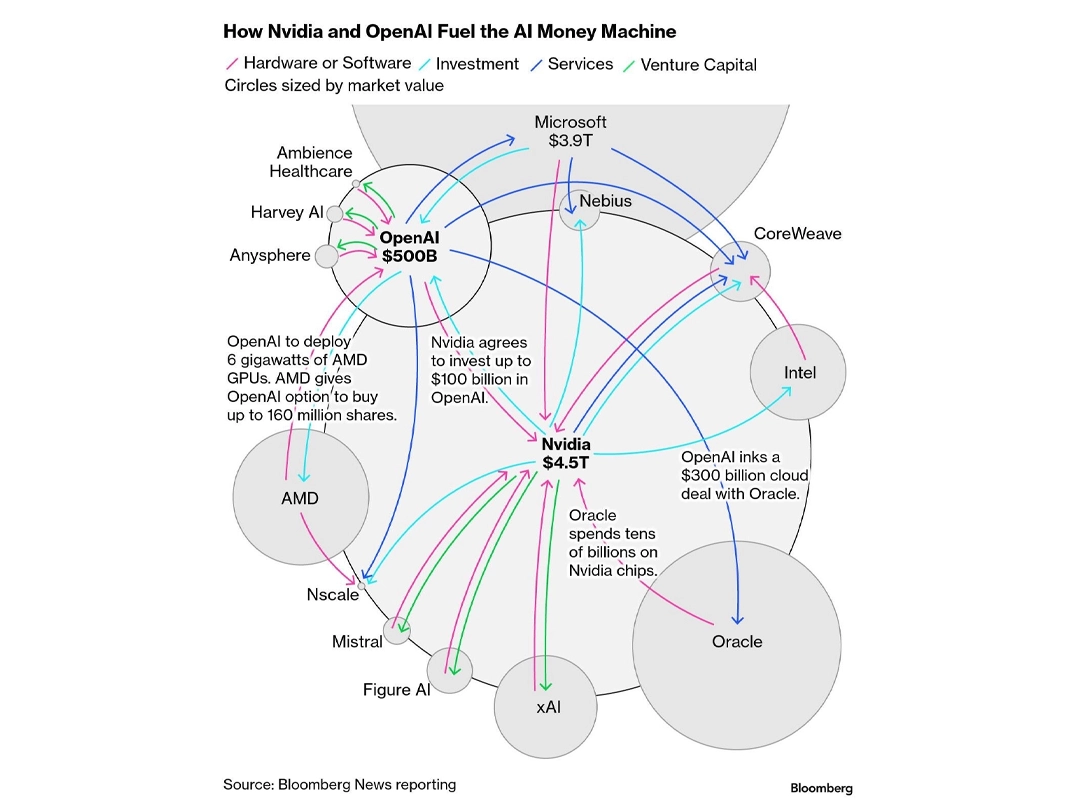
Однако независимо от того, является ли ИИ-сфера пузырём, это — крайне важная технология. Она уже меняет мир и будет менять его дальше. В нулевые пузырь доткомов лопнул, но интернет остался — и оказался намного важнее, чем предполагали инвесторы. То же может ждать ИИ.
То, что ИИ может быть пузырём, говорит только о том, что очень много людей хотят заработать на ИИ-сфере больше денег, чем в ней сейчас есть. Значимости технологии это не умаляет.
К тому же всегда остаётся вероятность, что какая-то новая технологическая революция уже где-то за углом. Nvidia, Microsoft и другие гиганты не сидят сложа руки.
Закончится ли кризис памяти, если ИИ-пузырь лопнет?
Главная причина дефицита памяти на рынке — бум ИИ. OpenAI и другим компаниям нужно оборудование для дата-центров — память. Они платят, платят много и платят сейчас. Поставщики памяти вроде Samsung и SK Hynix делают выбор в пользу ИИ-компаний, а не потребителей.
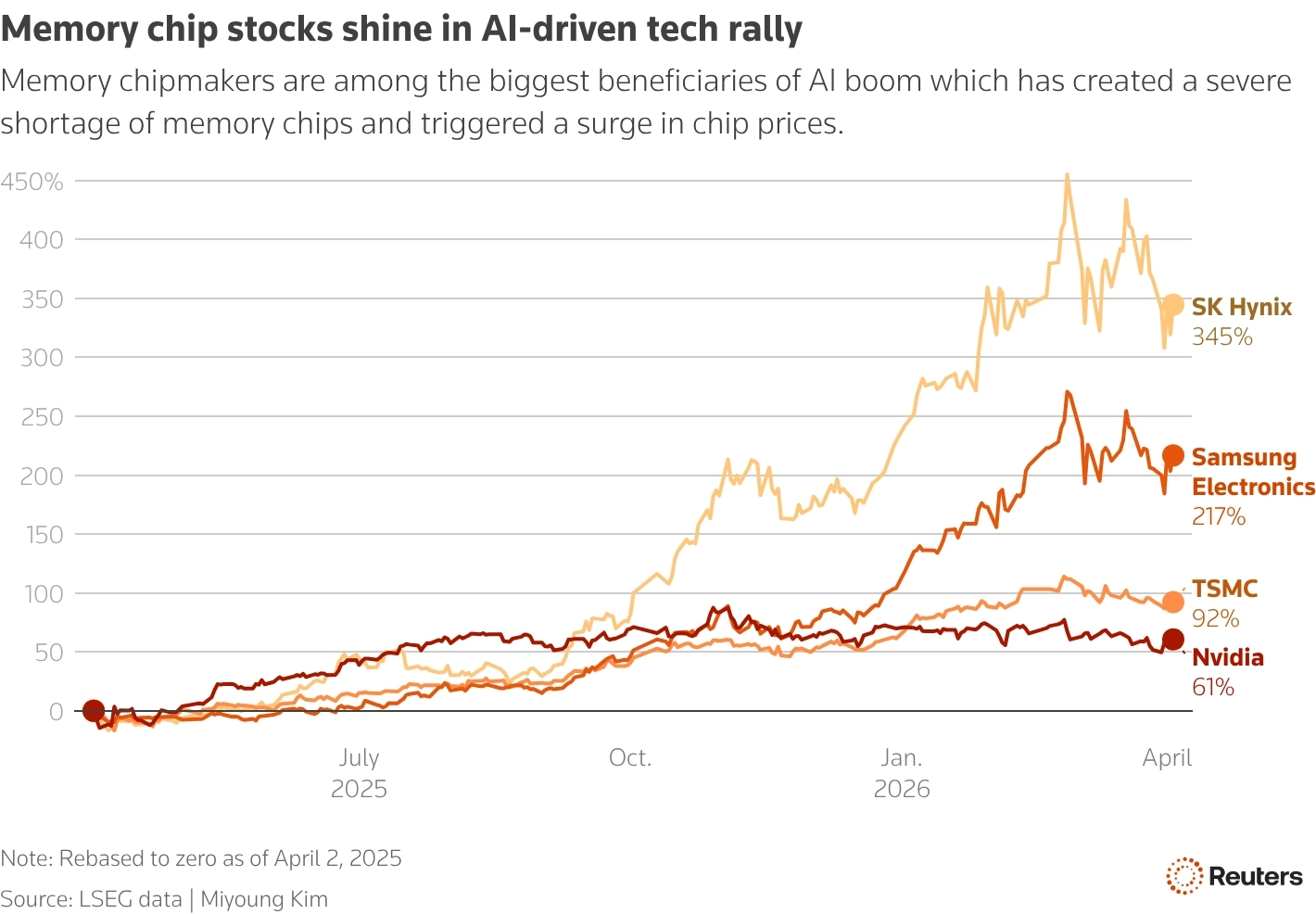
Со временем рынок может прийти в норму, если производители нарастят мощности и в ИИ-сфере снизится спрос на память. Однако, по прогнозам, дефицит ещё продлится годы, потому что ИИ-сфера продолжает расти.
Даже если ИИ окажется пузырём, который лопнет, технология никуда не денется, поэтому возвращения цен на уровень начала 2020-х в ближайшее время ждать не стоит.