
Возможность начать смотреть видео на телефоне по дороге с работы, «перекинуть» его на экран телевизора дома и продолжить просмотр с того же момента — это уже данность. Единая учётная запись для множества приложений и сайтов, общие подписки — тоже. Экосистемы научились обеспечивать бесшовный пользовательский опыт на уровне интерфейсов.
Следующий шаг — единые рекомендации: предпочтения из одного продукта учитываются в другом, даже если меняется формат контента. Воплотить эту идею в реальность помогают технологии понимания контента.
Как алгоритмы понимают контент
Современные ML-алгоритмы отлично умеют работать с пользователями — понимать их запросы, находить закономерности в предпочтениях и предсказывать интересы. Но чтобы рекомендации стали действительно точными и полезными, алгоритмы должны уметь понимать смысл самого контента: его тему, контекст и даже эмоциональный тон.
Речь идёт о почти человеческом уровне восприятия. Задача сама по себе сложная, особенно когда нужно анализировать контент разных форматов: от текстовых постов до видео.
Чтобы подобраться к решению, сначала нужно определить, какие компоненты составляют любую контентную единицу: визуальный ряд, речь, тексты, заголовки, описания, аудио. Всё это называют модальностями.
Классические нейросети работают с одной модальностью: текстовая модель читает подписи, компьютерное зрение анализирует картинку. Такой подход не позволяет сопоставлять сигналы разного рода между собой. Из-за этого система легко ошибается — например, считает похожими ролики с одинаковыми названиями, но совершенно разным содержанием.
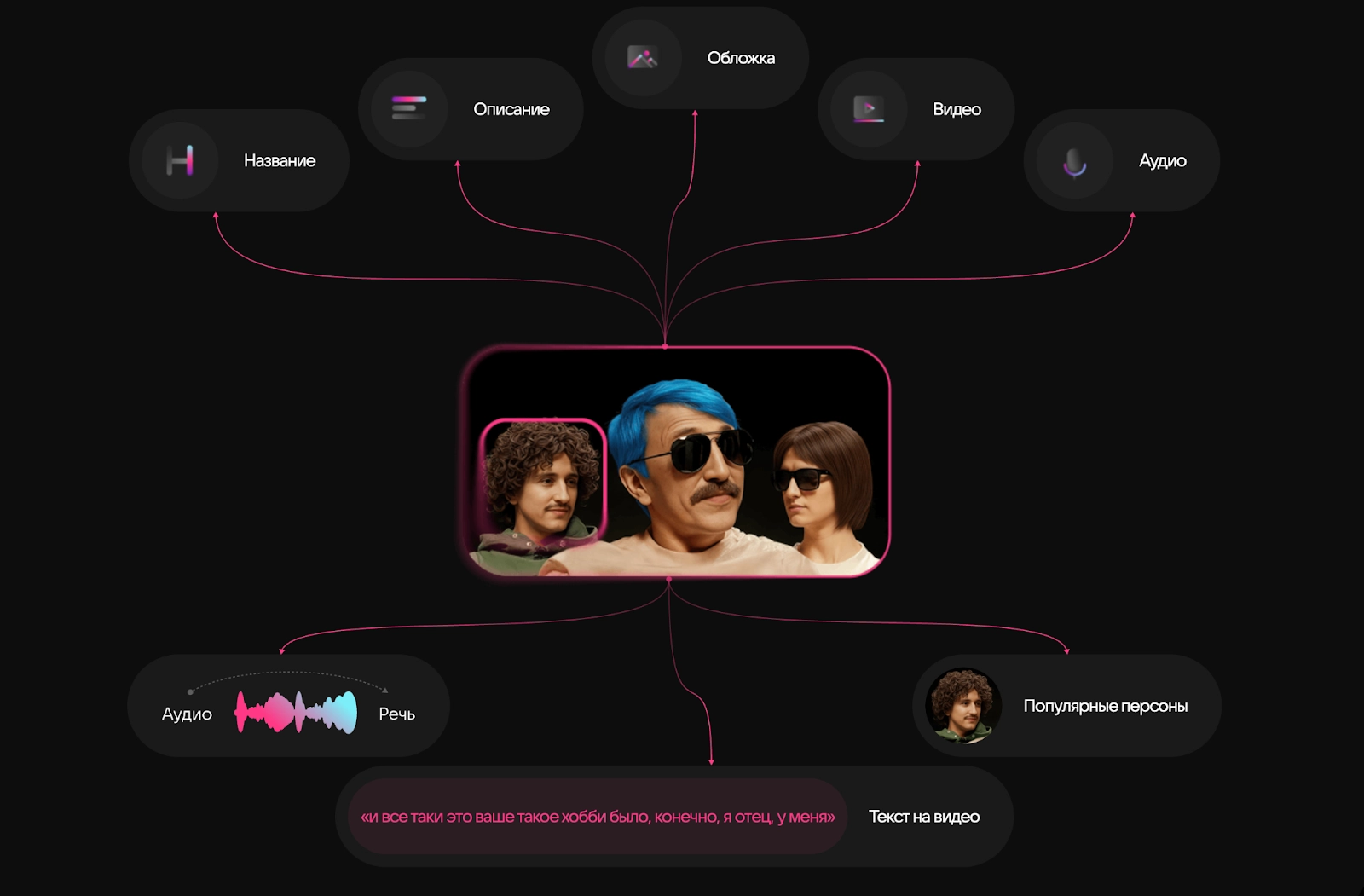
Чтобы рекомендательная система могла сопоставлять их между собой, находить связи между контентом и на их основе делать выводы, используются мультимодальные модели.
Они устроены иначе.
«Каждая модальность обрабатывается независимо, а затем все сигналы объединяются в единое смысловое представление — так называемый мультимодальный эмбеддинг. Это компактное числовое представление ролика, которое отражает его тему, визуальный стиль и общий контекст. Мультимодальная контентная модель работает, например, в „VK Видео“. В итоге алгоритм получает компактное описание контента и может сравнивать ролики не только по визуальным признакам, но и по смыслу»— Илья Алтухов, руководитель отдела экспериментальных технологий в направлении рекомендаций AI VK
Представление в виде эмбеддингов также позволяет рекомендательной системе сравнивать разные форматы контента: посты, клипы и длинные видео.

«Чтобы алгоритм не просто „видел“ текст, картинки и видео по отдельности, а понимал связь между ними, мы в VK используем contrastive learning — подход, при котором модель учится учитывать не только сходства, но и различия. Во время обучения эмбеддинги разных модальностей одного и того же ролика сближаются между собой, а несвязанный контент, наоборот, разводится. За счёт этого модель учится выстраивать прочные смысловые связи между сигналами разной природы»— продолжает эксперт
Что это даёт пользователю
Мультимодальная контентная модель позволяет рекомендательной системе работать со смыслами и быстро предлагать свежий, релевантный контент. Объединяя визуальные, текстовые и аудиосигналы, модель понимает, о чём материал, сразу после загрузки и до того, как его посмотрят и оценят первые зрители.
Мультимодальные модели также делают возможным поиск по примеру или даже настроению. Пользователь может загрузить фотографию и найти видео с похожей визуальной стилистикой, подобрать ролики с похожим саундтреком по аудио или найти контент со схожим сюжетом по текстовому описанию. Такой сценарий позволяет искать не словами, а ассоциациями через изображение, звук или смысл.
Ещё новый подход ускоряет выявление нежелательного контента, например, ролики с нейтральным визуалом, но ненормативной лексикой, или изображения с текстом, нарушающим правила платформы.
Наконец, открывается путь к кросс-форматным рекомендациям. Унифицированное числовое представление контента упрощает его сопоставление на разных площадках и построение единой системы рекомендаций. Для пользователя это выглядит примерно так: лайкнул лонгрид про путешествия во «ВКонтакте» — в рекомендациях «VK Клипов» появляется ролик с видами Алтая. Предпочтения, сформированные в одном сервисе, начинают работать в других.
Мультимодальное будущее
В перспективе рекомендации станут интерпретируемыми: вместо «Вам может понравиться» пользователь увидит объяснение — «Рекомендуем это, потому что вы оценили сцену с горами в прошлом ролике».
А ещё мультимодальные модели смогут не только подбирать существующий контент, но и генерировать свой: например, создавать коллажи из кадров любимых авторов, формировать плейлисты под контекст пользователя (время суток, местоположение, погоду) или генерировать краткие саммари. Похожие функции уже появляются на отдельных платформах и становятся новым уровнем персонализации.
«Пока потенциал мультимодальных моделей не используется на все 100%. Но уже сейчас понятно, что чем лучше мы понимаем тонкие смыслы контента и интент пользователя ‒ тем лучше становятся рекомендации. В ближайшие годы такие модели перейдут от роли “умного фильтра” к роли персонального ассистента, который сможет не только находить, подбирать, но и объяснять рекомендации»— подытоживает Илья Алтухов