
Задача распознавать речь есть у огромного числа сервисов: это и клавиатуры с функцией голосового ввода, и мессенджеры, которые расшифровывают аудиосообщения, и, конечно, виртуальные ассистенты.
Как умные колонки понимают человека и с какими проблемами сталкиваются разработчики, рассказывает Никита Рыжиков, руководитель службы технологий голосового ввода в «Алисе».
Как устроено распознавание речи
Технологии ASR (Automatic Speech Recognition) развиваются давно и с разной степенью успешности, но в последние годы эта сфера сильно продвинулась в качестве — во многом благодаря развитию нейросетей.
Чтобы машина начала распознавать речь необходимо сделать несколько шагов. Для начала акустические колебания давления с помощью микрофона и усилителя оцифровываются, превращаясь в последовательность цифр. Такое представление называется волновой формой. Волновая форма на примере слова Алиса изображена на рисунке:
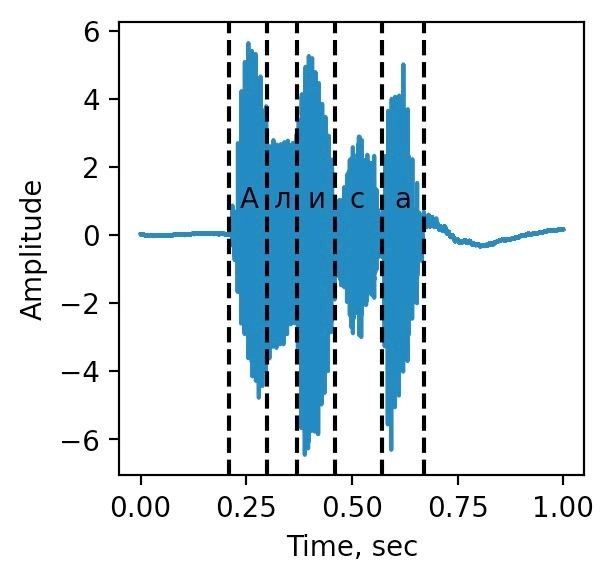
Чтобы алгоритмам было удобнее работать с этими данными, обычно к ним применяют преобразование Фурье, которое превращает звук в набор частот — спектр. Такое представление лучше, так как использует свойства распространения и генерации акустических волн. Последовательное применение преобразования Фурье к сигналу называется спектрограммой и изображено на рисунке:
Однако получившийся график не идеально отражает то, как звуки воспринимаются людьми. Дело в том, что у человеческого уха есть свои особенности, появившиеся в ходе эволюции: например, мы хорошо различаем звуки на низких частотах и практически не разбираем на высоких.
То есть любой музыкант отличит звук в 400 Гц от 440 Гц, но услышать разницу между 9 500 Гц и 10 000 Гц сложнее, они сольются в высокочастотный писк. Поэтому на получившийся спектр трансформируют в мел-спектрограмму — она учитывает эту нелинейность человеческого слуха. При использовании таких данных машина работает с теми частотами, которые значимы для человека, поэтому и качество результата выше.
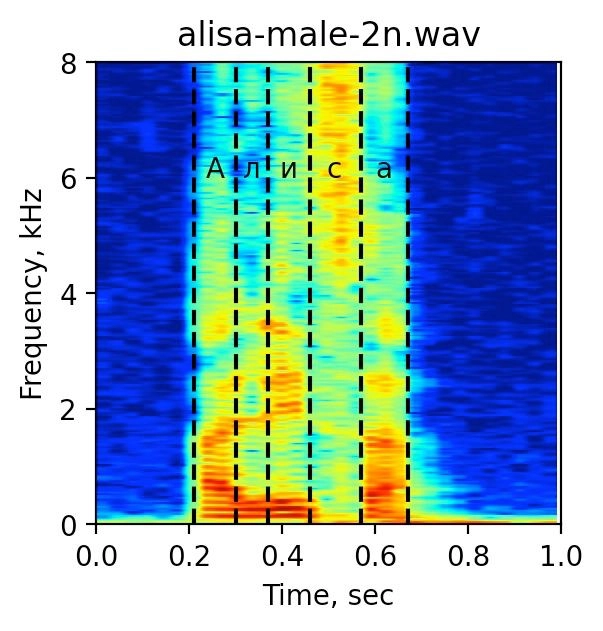
Такое представление помогает машине лучше распознавать речь, так как в ходе эволюции наш слух подстраивался хорошо слышать речь, а речь — чтобы её хорошо мог различать слух. Такое представление сигнала называется мел-спектрограммой и пример такого представления для слова Алиса приведено на рисунке:

Со стороны мел-спектрограмма выглядит как довольно красивая картинка — именно её анализируют нейросети для распознавания текста. Те или иные паттерны на таком изображении может выделить даже человек. Например, ребята, которые работают над качеством распознавания команд, могут по картинке узнать слово «Алиса», потому что видели его много раз в разных вариантах.
С такими вводными работает любой сервис — от мессенджера до приложения для заметок. Но в случае виртуальных ассистентов есть много дополнительных сложностей, которые нужно учитывать при разработке.
Особенности работы виртуальных ассистентов
Специфичные условия. Виртуальные ассистенты чаще всего живут в умных колонках, а значит, люди общаются с ними в разных бытовых ситуациях: они могут стоять рядом, кричать из соседней комнаты или вообще мыть посуду. Чтобы нейросеть могла распознавать команду во всех этих случаях, нужен большой объем данных, записанных в максимально приближенных условиях. Важно даже, чтобы микрофон был тот же, что используется в самой колонке.
Активация. Виртуальный ассистент может откликнуться, когда обращались не к нему, либо наоборот проигнорировать команду — и то, и другое будет некомфортно для пользователя. Поэтому важно, чтобы нейросеть точно распознавала команду активации.
Фоновый шум. В доме всегда что-то происходит: общаются члены семьи, разговаривает телевизор, с улицы доносится шум. Для комфорта пользователя колонка должна уметь распознавать запрос игнорируя на бытовые шумы.
Персонализация. Когда виртуальные ассистенты были только в телефоне, проблемы с определением говорящего не было. Но с появлением умных колонок возникла необходимость отличать, кто с ней разговаривает — например, чтобы не включать ребенку взрослый контент или чтобы понять, кто из членов семьи поставил лайк понравившейся песне.
Как распознавание речи развивается сейчас
Поговорить с виртуальным ассистентом можно было и в 2019 году, но сейчас их качество шагнуло вперед. Общаться с колонкой становится все проще и проще, а вот делать улучшения — сложнее и сложнее.
Для дальнейших разработок мы нуждаемся во все более точной разметке данных. Например, это важно для идентификации пользователя. Один и тот же человек может по-разному звучать в течение дня, а голоса родственников бывают очень похожи между собой. Сейчас нейросеть отличает людей не хуже среднего человека, но чтобы она решала более сложные задачи персонализации (например, отличала по голосу мать и дочь, которых путают по телефону знакомые) обучающий датасет должен быть очень качественным. Сейчас мы ищем разные инструменты, которые помогут решить эту задачу.
Несмотря на все сложности, эта сфера развиваются быстро. Например, перспективы для развития есть у объединения голосовых технологий с большими языковыми моделями (LLM), такими как ChatGPT и YandexGPT. Сейчас задачи решаются последовательно: одна нейросеть переводит звук в текст, другая готовит ответ, третья синтезирует речь. Но LLM сейчас становятся настолько качественными, что они могут сократить этот каскад действий — такой end-to-end подход сможет решать задачи быстрее и эффективнее. Например, весьма вероятно, что впечатляющие демо от OpenAI, которое компания показала весной, сделано на основе этой технологии.